AWS Solutions Architect Associate Certification (SAA-C03)
Preparing for SAA-C03 exam.

Preparing for SAA-C03 exam.
Source: https://www.youtube.com/watch?v=c3Cn4xYfxJY&t=453s (in progress, 1:03:42:56)
Cert page: https://aws.amazon.com/certification/certified-solutions-architect-associate/ Domain 1: Design Secure Architecture (30%) Domain 2: Design Resilient Architecture (26%) Domain 3: Design High-Performing Architecture (24%) Domain 4: Cost-Optimized Architectures (20%)
Connect to your AWS account using CLI + Gitpod
CLI page: https://awscli.amazonaws.com/v2/documentation/api/latest/reference/index.html#
Connect your github to gitpod. Then, set up a yml for your env.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
tasks:
- name: utils
before: |
sudo apt-get install tree
- name: aws-cli
env:
AWS_CLI_AUTO_PROMPT: on-partial
AWS_DEFAULT_REGION: us-east-1
before: |
cd /workspace
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
cd $THEIA_WORKSPACE_ROOT
Useful env tricks
- export
AWS_CLI_AUTO_PROMPT=on-partialto get help withawscommand line env | grep AWS_to peek at any AWS env variables- By default files in
/tmp/are cleaned up after 10 days, and those in/var/tmpafter 30 days.
You also need to run aws configure to connect to your account using you AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY. You may create a user using IAM > Users > Create User. Give it AdministratorAccess (or whatever you want) then under Security Credentials, click create access key.
Useful stuff to know
JMESPathhttps://jmespath.org/shebanghttps://en.wikipedia.org/wiki/Shebang_(Unix)- bash (Bourne Again Shell) vs sh
jqhttps://jqlang.github.io/jq/ allows for easy json handlingfilteris usually server side; whereasqueryis client sidemavenhttps://maven.apache.org/ orgradlehttps://gradle.org/ (tools to assemble packages for java)md5sumWORMWrite Once, Read Many. Storage compliance feature that makes data immutable. Useful in healthcare and financial industries.
Intro to S3
Object-basedstorage is a data storage architecture that manages data as objects.- S3 provides unlimited storage
Objects
- Objects contain your data and consist of:
keythe name of the objectvaluethe data itself made up of a seq of bytesversion idapplicable whenversioningis enabledmetadataadditional info
- range between 0 bytes to 5 terabytes

Bucket Folders
Foldersarezero-byteobjects with a name that ends in a/- Not independent identities but just s3 objects
- Don’t contain anything; they can be neither full nor empty
- They aren’t ‘moved’, s3 objects with same prefix are renamed
Object Etags
Ref: https://github.com/ExamProCo/AWS-Examples/tree/main/s3/etags
- entity tag (hash of the object’s content not its metadata)
- response header that represent a resource that has change (w/o need to download)
- The value of an etag is represented by a hashing function (MD5 or SHA-1)
- Part of
HTTPprotocol; they are also used for revalidating cache systems - Help with programmatically detect change in objects’ content
1
2
3
4
5
6
resource "aws_s3_object" "object" {
bucket = aws_s3_bucket.default.id
key = "myfile.txt"
source = "myfile.txt"
etag = filemd5("myfile.txt") # <---
}
Note: this is done using
terraformand CANNOT be done usingcfnbecause objects are not infrastructure in AWS (i.e.AWS::S3::Objectdoes not exist)
Object Checksums
Ref: https://github.com/ExamProCo/AWS-Examples/tree/main/s3/checksums
Checksumsensuredata integrityof the file in cases of in-transit loss of data- AWS S3 uses checksums for upload/download of files
- Available Algorithms:
- CRC32 (Cyclic Redundancy Check)
- CRC32C
- SHA1 (Secure Hash Algo)
- SHA256
1
2
3
4
5
6
7
8
sha1sum myfile.txt
aws s3api put-object \
--bucket="bucket-name" \
--key="myfilesha1.txt" \
--body="myfile.txt" \
--checksum-algorithm="SHA1" \
--checksum-sha1="YzI4Y2NjMmM1ZTIxNDAzNjgwNjAxNGRmOWZiNDM2MzRmM2U3NzBiMg=="
Object Prefixes
Ref: https://github.com/ExamProCo/AWS-Examples/tree/main/s3/prefixes
- part of the object
keyname. (\is considered a delimitator) - used to organize, group, and filter
- NOT true folders
- no limit for # of delimitators but object’s
keyname cannot exceed1024bytes
Object Metadata
Ref: https://github.com/ExamProCo/AWS-Examples/tree/main/s3/metadata
- 2 types:
system defined- AWS controls
- Usually, you can’t edit those

user defined- Must start with
x-amz-meta- 
- Must start with
- View object
aws s3api head-object --bucket <bucketName> --key <objectKey>
Object Lock
- Prevent deletion of objects
- Must be turned on at the creation of a bucket
- Object Lock is
SEC 17a-4,CTCC, andFINRAregulation compliant - (temporary or indefinite)
WORMmodel (just likeS3 Glacier) - 2 Types of holds:
Retention periods(locked for a set of time)Legal holds(remains locked until removed) - S3 bucket with
LockON canNOT be used as destination for server access logs - Can ONLY be done through
AWS API(CDK or CLI), not AWS Console
S3 Bucket
- S3 is a universal namespace!!! ~ think domain names
- Buckets must be emptied before deleted
Security:
- Bucket Policies: Define permissions for an entire s3 bucket using
JSON(IAMpolices scoped around a bucket) - Access Control List (ACL) : Provide a legacy method to manage access permissions on ind. objects and buckets (not recommended to use).
- legacy feature to grant other AWS accounts basic read/write permissions (don’t use please).
- cannot grant/deny permissions to users in you account
Ref: https://github.com/ExamProCo/AWS-Examples/tree/main/s3/acls
1 2 3 4 5
aws s3api put-public-access-block \ --bucket <bucketname> \ --public-access-block-configuration "BlockPublicAcls=false,IgnorePublicAcls=false,BlockPublicPolicy=true,RestrictPublicBuckets=true" aws s3api get-public-access-block --bucket <bucketname>
1 2 3
aws s3api put-bucket-ownership-controls \ --bucket <bucketname> \ --ownership-controls="Rules=[{ObjectOwnership=BucketOwnerPreferred}]"
1 2 3
aws s3api put-bucket-acl \ --bucket <bucketname> \ --access-control-policy file:///workspace/AWS-Examples/s3/acls/policy.json
1 2 3
touch bootcamp.txt aws s3 cp bootcamp.txt s3://<bucketname> aws s3 ls s3://<bucketname>
- AWS PrivateLink for Amazon S3: enables private network access to s3, bypassing the public internet for enhanced security (not free and robust).
- Cross-Origin Resource Sharing (CORS): Allows restricted resources on a web page from another domain to be requested.
- S3 Block public access: Turned on by default
- 4 options if turned off, (1/2) New/Any ACLs (3/4) New/Any Bucket Policies or Access Points
- IAM Access Analyzer for S3: Analyzes resources to help you mitigate potential access risks
- Internetwork Traffic Privacy: ensures data privacy by encrypting data moving between AWS services and the internet.
- Object Ownership: manages data ownership between AWS accounts when objects are uploaded to S3 buckets
- Access Points: simplifies managing data access at scale for shared datasets in S3
- Access Grants: providing access to S3 data via directory services (e.g. Active Directory)
- Versioning: Preserves, retrieves, and restores ever version of every object in an S3 bucket (off by default).
- MFA delete: Adds an additional layer of security by requiring MFA for deletion of objects.
- Object tags: Provides a way to categorize storage by assigning key-value pairs to s3 objects.
- in-transit encryption: protects data by encrypting it as it travels to and from s3 over the internet
- server-side encryption: (enforced) automatically encrypts data when writing it to s3 and decrypts when downloading
- client-side encryption: encrypts data client-side before uploading and decrypts after downloading
- compliance validation for s3: ensures service meet compliance req like
HIPAA,GDPR, etc. - Infra. security: ensures data integrity and availability
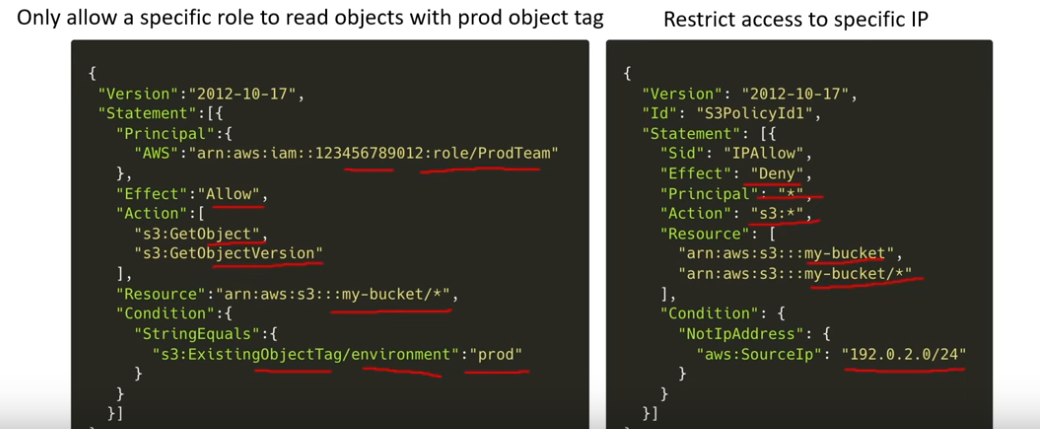
Bucket policy
- S3 Bucket Policies are more convenient than IAM policies
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
{ "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "<account ARN>" }, "Action": [ "s3:ListBucket", "s3:GetObject", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::<somebucket>", "arn:aws:s3:::<somebucket>/*" ] } ] }
IAM policy

S3 Access Grants
- This is used for mapping identities in a
directory service(AD, Okta) for S3 access.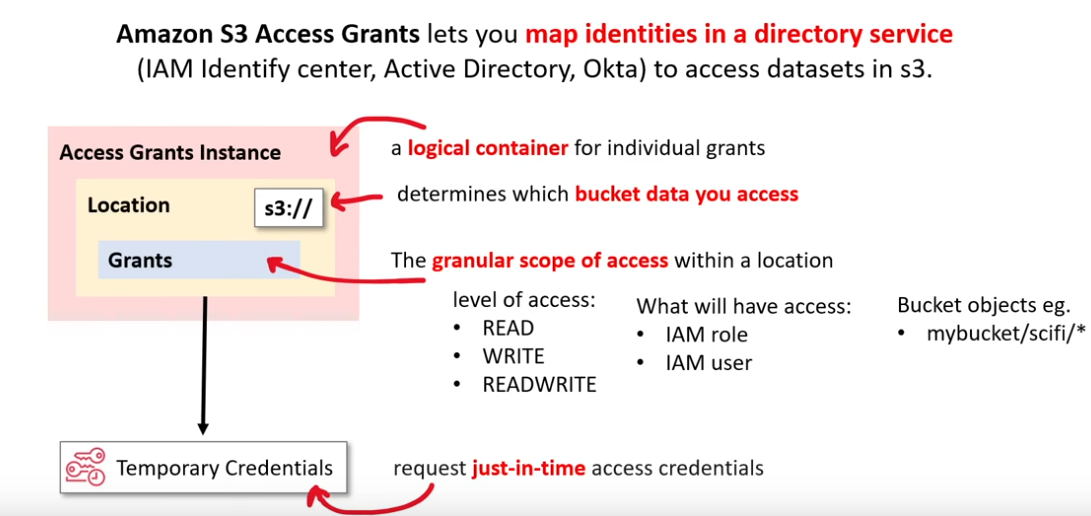
IAM Access Analyzer for S3
- Create an
analyzerin IAM Access Analyzer at the account lvl - It will alert you when s3 are exposed to the internet or other AWS accounts
Internetwork Traffic Privacy
- keeping data private as it travels across diff networks.
- AWS PrivateLine:
- This service is associated with a charge.
- Allows you to connect to an
Elastic Network Interface(ENI) directly to other AWS services. - It can connect to select 3rd party services via
AWS Marketplace - Has fine-grain permission via
VPC endpoint policies
- VPC Gateway Endpoint
- No charge.
- Allows you to connect a VPC directly to S3 or DynamoDB privately wiuthin the internal AWS network.
- Not cross-account
- Does not have fine-grain permissions
Encryption-in-Transit
Ref: https://github.com/ExamProCo/AWS-Examples/tree/main/s3/encryption
- Ensures data remains confidential and cannot be intercepted or viewed.
- Algorithms:
TLS(Transport Layer Security; version 1.3),SSL(Secure Sockets Layer) - encrypted by sender; decrypted by receiver
- Encryption-at-rest
- Client-Side Encryption (CSE): data encrypted by client; server cannot decrypt
- AWS and 3rd party CANNOT decrypt. Refer to
SDKfor this. Ref: https://github.com/ExamProCo/AWS-Examples/tree/main/s3/encryption-client
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
require 'aws-sdk-s3' require 'openssl' require 'pry' key = OpenSSL::PKey::RSA.new(1024) bucket = 'bucketname' object_key = 'hello.txt' # encryption client s3 = Aws::S3::EncryptionV2::Client.new( encryption_key: key, key_wrap_schema: :rsa_oaep_sha1, # the key_wrap_schema must be rsa_oaep_sha1 for asymmetric keys content_encryption_schema: :aes_gcm_no_padding, security_profile: :v2 # use :v2_and_legacy to allow reading/decrypting objects encrypted by the V1 encryption client ) # round-trip an object, encrypted/decrypted locally resp = s3.put_object(bucket: bucket, key: object_key, body:'handshake') puts "PUT" puts resp resp = s3.get_object(bucket: bucket, key: object_key).body.read puts "GET WITH KEY" puts resp #=> 'handshake' # reading encrypted object without the encryption client # results in the getting the cipher text resp = Aws::S3::Client.new.get_object(bucket:bucket, key:object_key).body.read puts "GET WITHOUT KEY" puts resp
- AWS and 3rd party CANNOT decrypt. Refer to
- Server-Side Encryption (SSE): data encrypted by server; server decrypts data when requested
- Always-on for all new S3 objects
- specify using
aws s3api put-object --server-side-encryption - Does NOT encrypt
metadata - Types:
SSE-S3: S3 manages the keys, encrypts usingAES-GCM (256-bit)Algo.- encrypts each object w/ a unique
key - uses envelope encryption
- automatically and regularly rotates
key - improved performance from
bucket key - default option
- no additional cost
- uses
256-bit Advanced Encryption Standard Galois/Counter Mode (AES-GCM)(akaAES256)
- encrypts each object w/ a unique
SSE-KMS:KMSand you manage the keys- use a
KMSkey managed by AWS to achieve greater regulatory compliance - choose the key to encrypt your object
- can automatically rotate keys
- create policy to control who can decrypt using the key
- additional cost
- must be same region as bucketp
- improved performance from
bucket key - to upload, you need
KMS:GenerateDataKey - to download, you need
KMS:Decrypt1
aws s3api put-object --server-side-encryption "aws:kms" --ssekms-key-id <id>
- use a
SSE-C: Customer provided keys (you worry about it)- You provide a key that gets used to apply
AES256encryption on your data - provide key everytime you retrieve objects
- no cost but all maintenance on you
- S3 will store a randomly salted
Hash-based Message Auth Code (HMAC)of your key to validate future requests. - with
bucket versioningyou can encrypt diff object versions with diff keys !!!
- You provide a key that gets used to apply
DDSE-KMS: Dual-layer server-side encryption. Encrypts client side then server side.SSE-KMS+ client-side encryption throughKMS- data encrypted twice
- additional cost
CMK=>Customer Managed Key
- Client-Side Encryption (CSE): data encrypted by client; server cannot decrypt
S3 Bucket Key
- Encryption can be applied globally, not just on object level
SSE-KMS, an individual data key is used on every object request- S3 has to call
KMSeverytime a request is made. KMScharges on the number of request, so this will add upS3 bucket keyallows you to generate a unique short-lived bucket-level key that is stored in S3 per requester.- This will reduce cost by up to 99% and decrease request traffic and improve overall performance
CORS
Ref: https://github.com/ExamProCo/AWS-Examples/tree/main/s3/cors
- Cross-Origin Resource Sharing
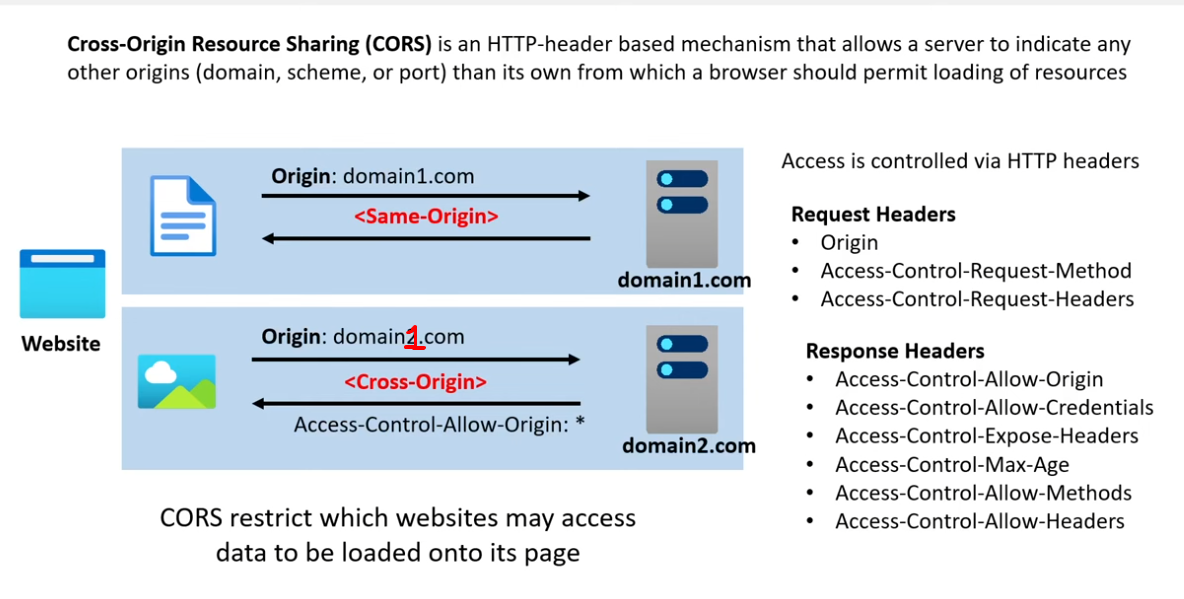
- S3 allows you to set CORS config to a S3 bucket with static website hosting so diff origin can perform HTTP requests from your S3 statis website.
1 2 3 4 5 6 7 8 9 10 11
{ "CORSRules": [ { "AllowedOrigins": ["<Invoke URL for the API Gateway>"], "AllowedHeaders": ["*"], "AllowedMethods": ["PUT", "POST", "DELETE"], "MaxAgeSeconds": 3000, "ExposeHeaders": ["x-amz-server-side-encryption"] } ] }
Data Consistency
- S3 offers
Strong consistencyfor read, write, and delete
Object Replication
- Types
- Cross Region Replication:
- Same Region Replication:
- Bi-Directional Replication:
- S3 Batch Replication:

S3 Versioning
- recover more easily from unintended user actions
- portects against accidental deletion or overwrite
- once enabled, it cannot be disabled
- integrates with S3 Lifecycle rules
- MFA delete feature provides extra protection against deleltion
- Bucket can be in 3 states: (1) unversioned (2) versioned (3) versioned suspended
S3 Life Cycle
- allows you to automate storage class, archival, deletion of objects
- can be used with versioning
- two types of actions: (1) transitioning (e.g. move) (2) expiring (e.g. delete)
- move current/noncurrent version of objs between storage classes
- delete expired versions, expire current version, delete noncurrent versions …
- filters:
- based on prefix, tags, or min/max size
S3 Transfer Acceleration
- bucket-level feature that provides fast and secure transfer of files over long distances
- uses CloudFront’s distributed
Edge Locationsto quickly enter Amazon Global Network https://s3-accelerate.amazonaws.comorhttps://s3-accelerate.dualstack.amazonaws.com- only supported on
virtual-hosted style requests - takes up to 20m to activate
- cannot contain
.(periods) and must beDNScompliant
S3 Presigned URL
- temp access to upload/download objects. Usually used to access private objects.
aws s3 presign s3://mybucket/myobject --expires-in 300
1
2
3
4
5
6
7
https://<mybucketname>.s3.<region>.amazonaws.com/<myobject>
?X-Amz-Algorithm=AWS4-HMAC-SHA256
&X-Amz-Credential=<your_aws_access_key><region>
&X-Amz-Date=<time stamp of when signature was created>
&X-Amz-Expires=<duration for which url is valid>
&X-Amz-SignedHeaders=host
&X-Amz-Signature=<generated_signature>
S3 Access Points
- named network endpoints that are attached to buckets that you can used to perform S3 object operations such as Get and Put.
- each access point has distinct network controls, block public accessm, and permissions via Access Point Policy
- usually, they are thought of as specific overrides to your bucket general policy
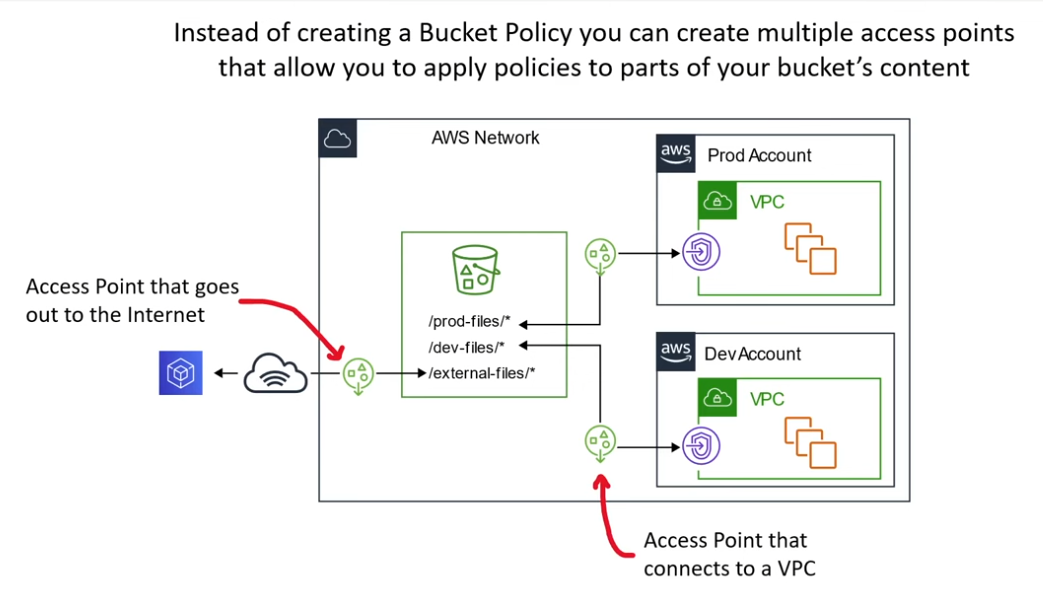
S3 Multi-Region Access Points
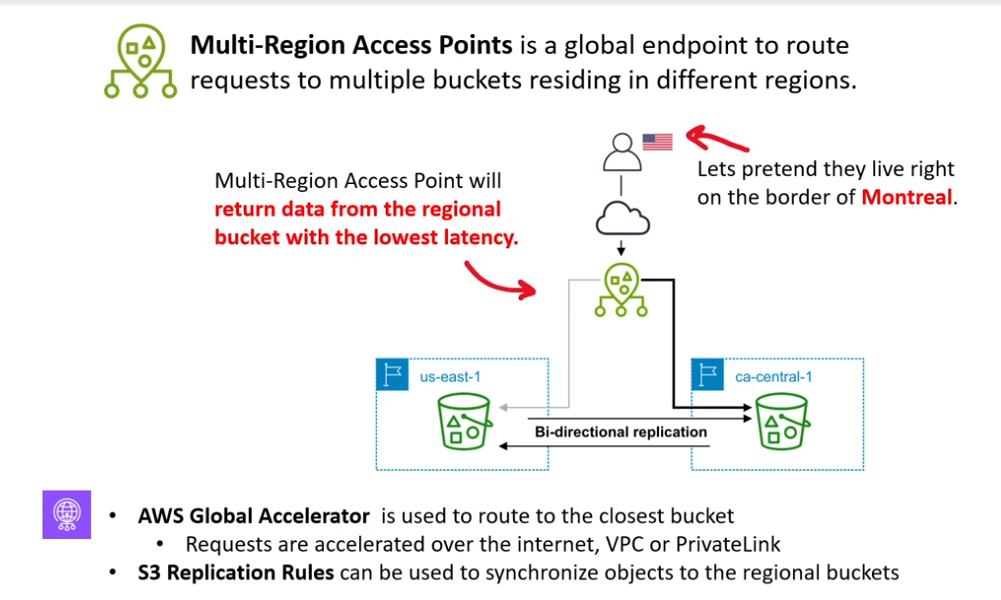
S3 Object Lambda Access Points
- helps transform data out of oyur bucket before sending it to some other entity
- for example, delete all personal/sensitive information o

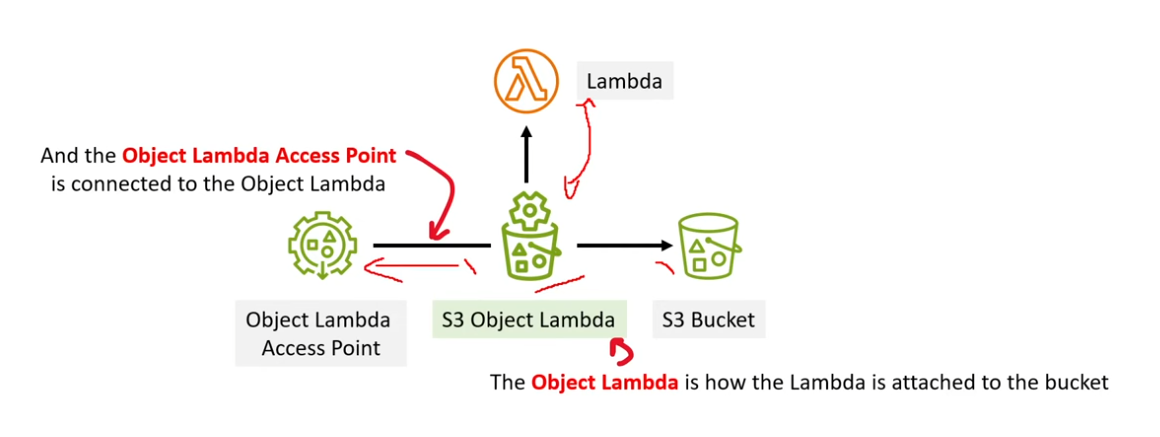
- for example, delete all personal/sensitive information o
Mountpoint for S3
- allows you to mount an S3 to your local linux file system
- can read up to 5tb, list, create new files
- cannot modify existing files, delete dirs, support symbolic links, support file locking
- only works with S3 Standard, Standard IA, One Zone IA, RRS (legacy), Glacier Instant Retrieval.
ideals for apps that dont need all the features but require S3’s elastic throughput to read and write large datasets.
1 2 3 4 5 6 7 8 9
wget https://s3.amazonaws.com/mountpoint-s3-release/latest/x86_64/mount-s3.rpm sudo yum install ./mount-s3.rpm mount-s3 --version mkdir ~/mnt mount-s3 mybucket ~/mnt cd mnt unmount ~/mnt
S3 Archived Objects

S3 Requesters Pay
- requesters will have to assume an IAM role. They cannot be anonymous.
- as simple as enable/disable
- You pay for storage; requesters pay for cost to download
- must include
x-amz-request-payerin their API request header - common trobleshooting:
403 Forbidden Request- did not include requester param
x-amz-request-payer - something wrong with IAM role
- request is anonymous
- request is SOAP
- did not include requester param
AWS Marketplace for S3

S3 Batch operations
- performs large-scale batch operations on S3 objects
- can also generate a completion report to audit the outcome of bulk operations
- for example:
- copy all objected listed to destination according to the manifest
- invoke lambda against each object
- replace all object tags
- replace access control list
- restore
- object lock retention for all objects
- object legal hold for all objects
S3 Inventory

S3 Select
- lets you used SQL to filter content of s3 objects

S3 Event notification
- allows bucket to notify other aws services about s3 event data
- events:
- new object created
- object removal
- restore objects
- replication events
- tagging event
- etc
- can trigger:
- sns
- sqs
- lambda
- event bridge
- etc
S3 Storage Class Analysis

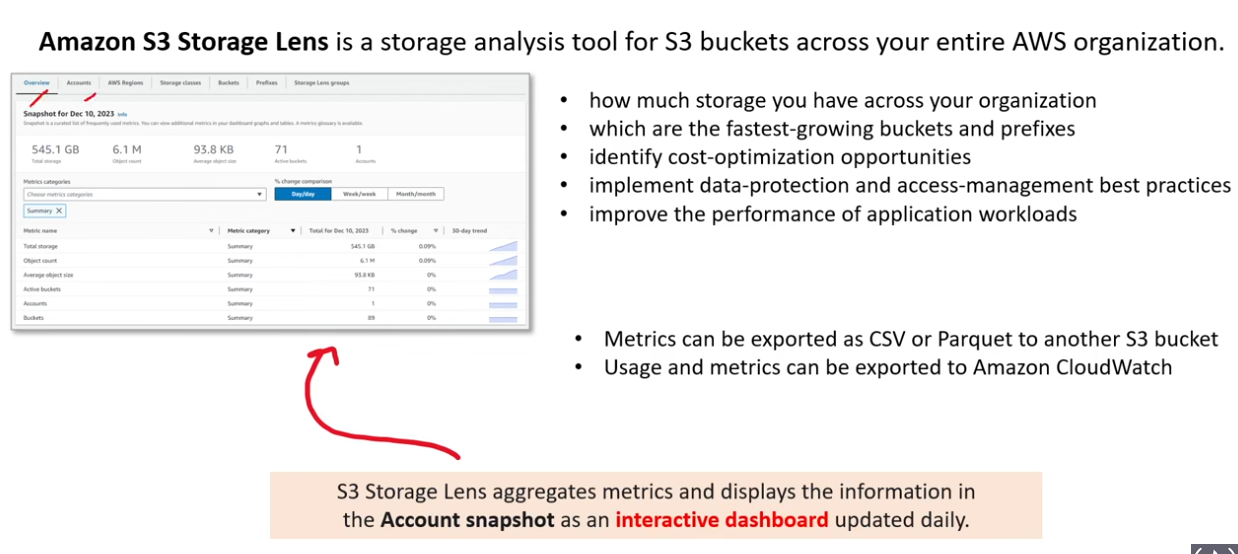
S3 Storage Lens
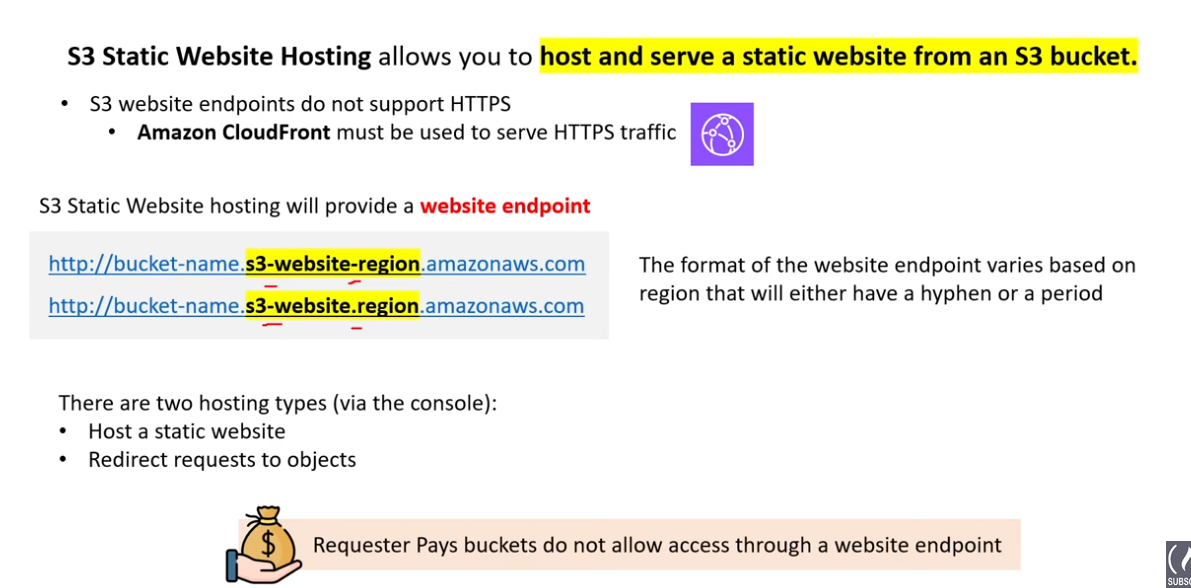
S3 Static Web Hosting
- host and serve static website from s3 bucket
- S3 endpoints only support HTTP; must use CloudFront for HTTPS
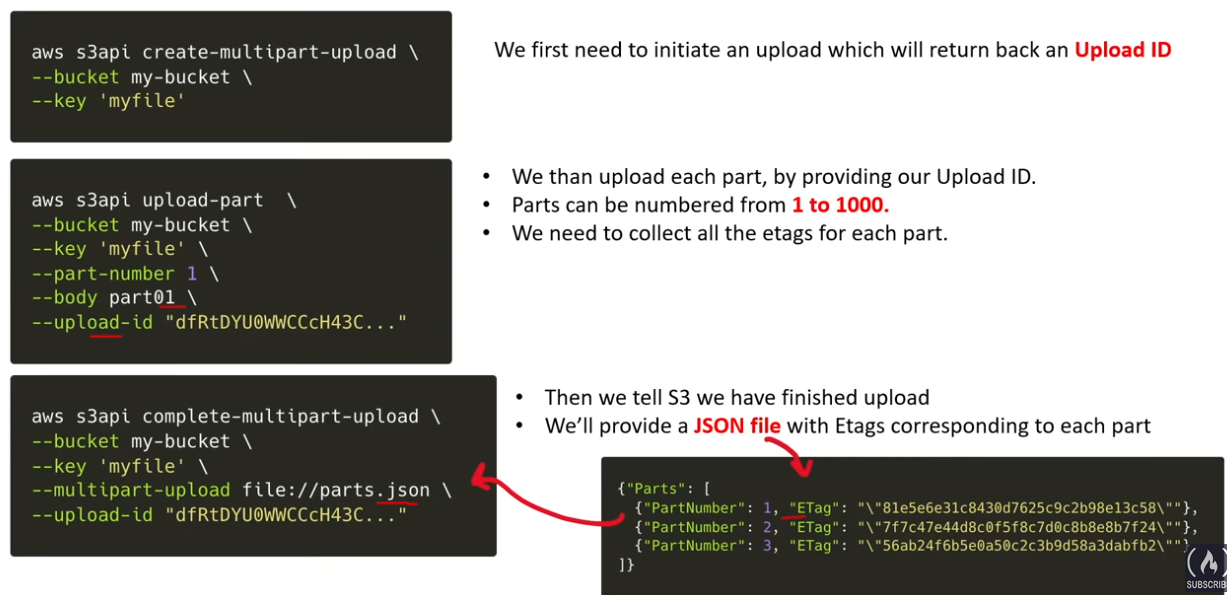
S3 Multipart Upload
Ref: https://github.com/ExamProCo/AWS-Examples/tree/main/s3/multipart-upload
- improved throughput, no expiry time for when to upload the parts
- use for file > 100MB
- parallelizable
- create upload id, divide file in some way, once all are uploaded notify aws so that it merges them
S3 Byte Range Fetching
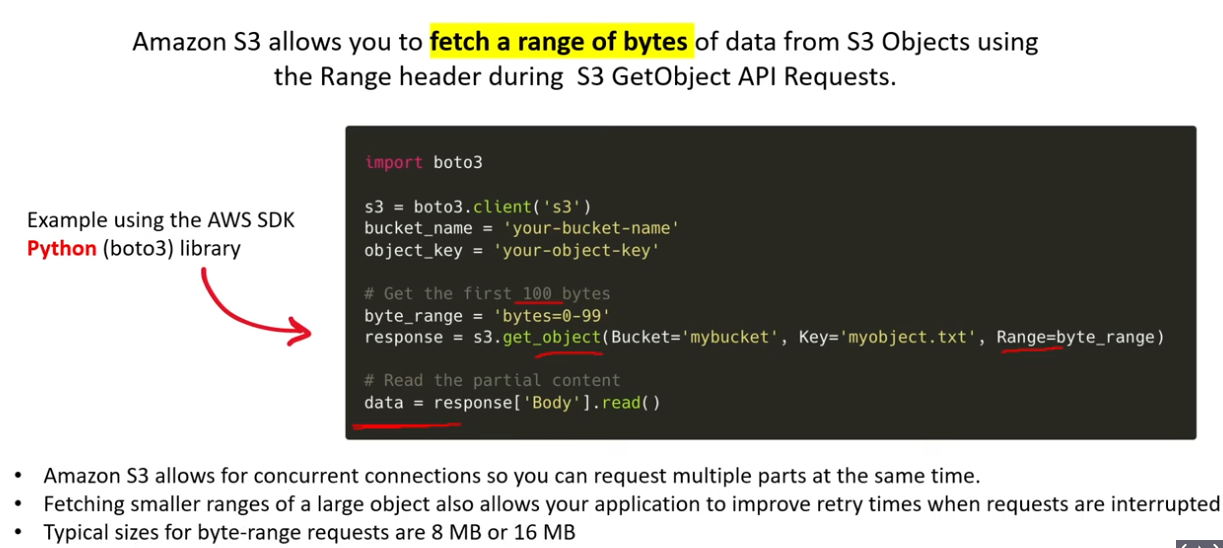
S3 Interoperability
- These are important to know !!

Types
General Purpose:- The vanilla Amazon S3 bucket type.
- Flat hierarchy (Folders here are basically
prefixes) - Used with all storage classes EXCEPT
S3 Express One Zoneclass - NO prefix limit
- Default 100 per account
- Scales horizontally.
Directory bucket(new – https://community.aws/content/2ZDARM0xDoKSPDNbArrzdxbO3ZZ/s3-express-one-zone?lang=en):- Amazon S3 bucket type that is used for workloads or performance-critical applications that require consistent single-digit millisecond latency on
PUTandGET. - Folder hierarchy
- Can ONLY be used with
S3 Express One Zoneclass - NO prefix limit
- Individual dirs can scale horizontally (adding additional nodes or machines to your infrastructure to cope with new demands).
- Default 10 per account
- Amazon S3 bucket type that is used for workloads or performance-critical applications that require consistent single-digit millisecond latency on
Bucket URI
- Uniform Resource Identifier (s3://examplebucket/file.txt)
Dualstack Endpoints
Standard Endpoint–>https://s3.us-east-2.amazonaws.com(handles onlyIPV4)
DualStack Endpoint–>https://s3.dualstack.us-east-2.amazonaws.com(handlesIPV4 & IPV6)
- Other Endpoints:
Static WebsiteFIPSS3 ControlsAccess Points
REST API Request Styles
- Virtual hosted-Style request
1 2 3 4 5
DELETE /puppy.jpg HTTP/1.1 Host: examplebucket.s3.us-west-2.amazonaws.com Date: Mon, 11 Apr 2016 12:00:00 GMT x-amz-date: Mon, 11 Apr 2016 12:00:00 GMT Authorization: authorization string
- path-style request (will be dicontinued)
1 2 3 4 5
DELETE /examplebucket/puppy.jpg HTTP/1.1 Host: s3.us-west-2.amazonaws.com Date: Mon, 11 Apr 2016 12:00:00 GMT x-amz-date: Mon, 11 Apr 2016 12:00:00 GMT Authorization: authorization string
Bucket Naming

Bucket Restrictions and Limitations
- By default, you can create up to
100buckets (you create a request to inc to1000) - Must be emptied before deleted
- No max bucket size, and no limit to # objects
- Objects can be between
0 to 5TBs(for >100MB objects, usemulti-partupload using CLI)
Storage Class
- This seems to be at the
object level!!
Ref: https://www.linkedin.com/pulse/understanding-amazon-s3-storage-classes-making-most-cloud-ajit-pisal/


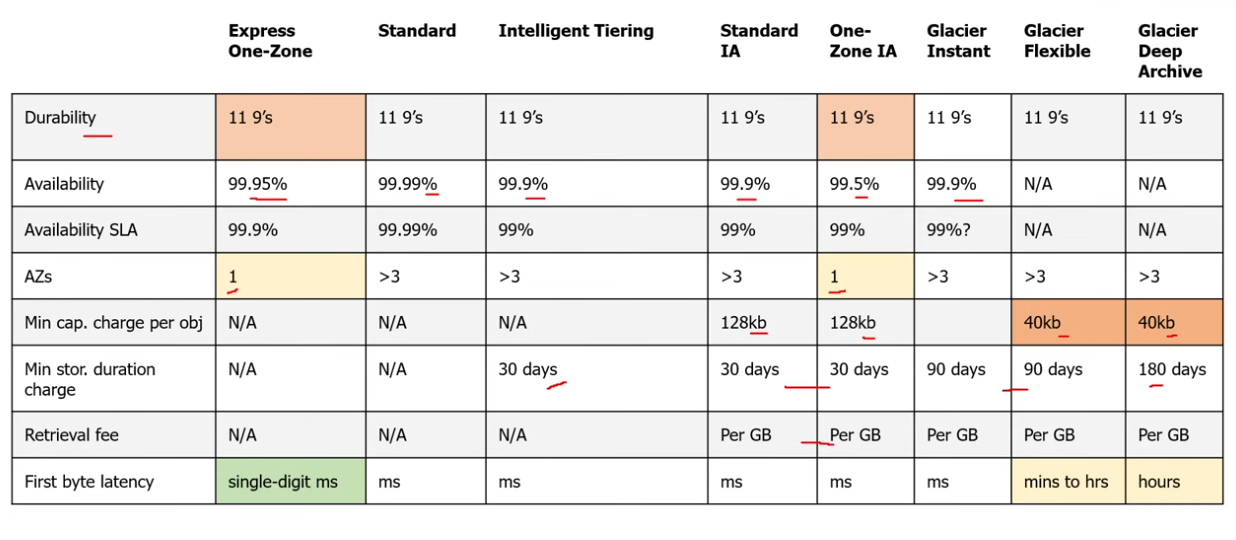
- Amazon S3 Standard: This is the default storage class, designed for frequently accessed data. It provideshigh durability, availability, and low latency. It’s an excellent choice for frequently updated data, such aswebsite content or application assets.

- Amazon S3 Intelligent-Tiering: This class automatically moves objects between two access tiers: frequent and infrequent access. It’s ideal for unpredictable workloads, as it adjusts storage costs based on usage patterns.

- Amazon S3 Standard-IA (Infrequent Access): storage class within Amazon Simple Storage Service (S3) designedfor infrequently accessed data. It offers a cost-effective storage solution while maintaining high durabilityand availability. While access times might be slightly slower compared to the standard storage class, it’s asuitable choice for data that isn’t regularly accessed but needs to be readily available when needed. This storage class is commonly used for archiving, backups, and storing data that is accessed intermittently. Itallows organizations to save on storage costs without sacrificing data integrity or accessibility.

- Amazon S3 One Zone-IA (Infrequent Access): If data can be recreated or is non-critical, this class offers alower-cost option. It stores data in a single availability zone, which reduces cost but sacrifices availability compared to the standard class.

- S3 Glacier Instant Retrieval:

- Amazon S3 Glacier Flexible Retrieval (formerly Glacier “Vault”): For long-term archival and data retention, Glacier offers extremely low-cost storage.Access times are in the range of minutes to hours, making it suitable for infrequently accessed data.
- Lore:
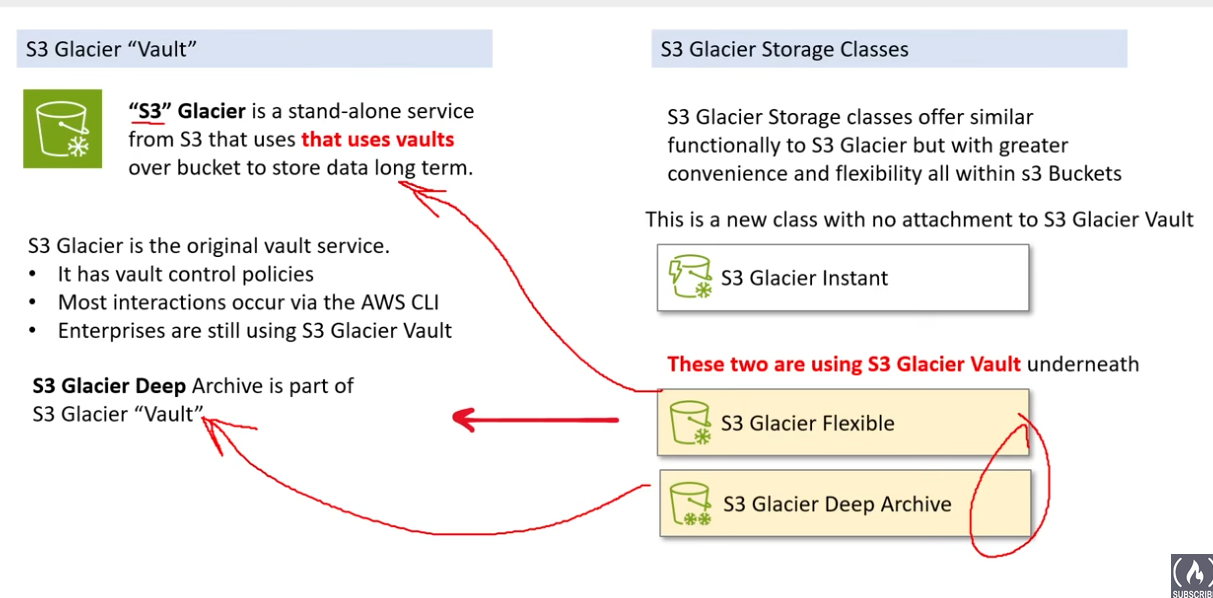

- Lore:
- Amazon S3 Glacier Deep Archive: Designed for truly long-term archival, this class provides the lowest storagecosts but with access times ranging from hours to even longer durations.

- Express One Zone (NEW)

S3 command-line
aws S3is high-level;aws S3apiis low-levelaws S3 lslist your S3 buckets. We also havecp,mv,rm…- sometimes, even the
latestdocs are outdated! (e.g.aws --outputdoes not work) Experiment and find out. aws S3 rm S3://mybucket/ --recursive --exclude "another/"to empty out a bucketaws S3 rb S3://mybucket/to delete bucketaws S3 sync someFile/ S3://mybucketnameaws s3 cp <fileName> s3://<bucketname> --storage-class STANDARD_IAchange storage classaws S3api create-bucket --bucket mybucketname --region us-east-1aws S3api list-buckets --query Buckets[].Name --output tableuses JMES conventionaws S3api list-buckets --query "Buckets[?Name == 'mybucketname'].Name"aws S3api get-object --bucket mybucketname --key fileNamedownloading S3 objects- you have to also set
--content-typeto, for example,plain/txt. It might not know automatically --bodyneeds to be set tofileName
- you have to also set
aws S3api list-objects --buckets mybucketname --query Contents[].Key- surprisingly, folders would be listed
S3 CLI
aws s3aws s3apiaws s3controlaws s3outposts
S3 bash scripting
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Check for bucket name
if [ -z "$1" ]; then
echo "There needs to be a bucket name eg. ./bucket my-bucket-name"
exit 1
fi
BUCKET_NAME=$1
# https://docs.aws.amazon.com/cli/latest/reference/S3api/create-bucket.html
# needed for anything but us-east-1
# --create-bucket-configuration="LocationConstraint=ca-central-1"
aws S3api create-bucket \
--bucket $BUCKET_NAME \
--query Location \
--output text
S3 SDK
Ruby
- Refer to https://github.com/ExamProCo/AWS-Examples/tree/main/S3/sdk/ruby
bundle initto create your gem filebundle installto install all your libsbundle exec ruby file.rbto run some .rb file
1
2
3
4
5
6
7
8
# frozen_string_literal: true
source "https://rubygems.org"
# gem "rails"
gem 'aws-sdk-S3'
gem 'pry' # debugging
gem 'nokogiri' # parsing (e.g. xml parsing)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
require 'aws-sdk-S3' # AWS SDK for S3 operations
require 'pry' # Interactive shell for debugging
require 'securerandom' # For generating secure random strings (UUIDs)
# S3 Bucket configuration
bucket_name = ENV['BUCKET_NAME'] # Fetching bucket name from environment variables
region = 'us-east-1' # AWS region where the bucket will be created
# Initialize AWS S3 client
client = Aws::S3::Client.new # Creating a new instance of the S3 client
# Create S3 bucket
resp = client.create_bucket({
bucket: bucket_name, # Name of the bucket
})
# binding.pry (for debugging)
# Determine the number of files to create and upload
number_of_files = 1 + rand(6) # Generating a random number between 1 and 6
puts "number_of_files: #{number_of_files}"
# Loop to create and upload each file
number_of_files.times.each do |i|
puts "i: #{i}"
filename = "file_#{i}.txt" # Generating a filename for each file
output_path = "/tmp/#{filename}"# Specifying the output path for the file
# Writing a unique UUID to each file
File.open(output_path, "w") do |f|
f.write(SecureRandom.uuid) # Write a random UUID to the file
end
# Open and read the file in binary mode, then upload it to S3
File.open(output_path, 'rb') do |f| # 'rb' mode for reading binary data
client.put_object( # Uploading the file to S3
bucket: bucket_name, # Bucket to upload to
key: filename, # Key (filename) for the object in the bucket
body: f # File content
)
end
end
Java
S3 IaS
S3 CFN
- Refer to https://github.com/ExamProCo/AWS-Examples/tree/main/S3/iac/cfn
cfn(Cloud Formation);iac(infrastructure as code)terraformis eventually not free but allows formulti-cloud;cfnis free withaws
1
2
3
4
5
6
7
AWSTemplateFormatVersion: "2010-09-09"
Description: A simple S3 bucket
Resources:
S3Bucket:
# https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-S3-bucket.html
Type: 'AWS::S3::Bucket'
# We don't need supply a Bucket Name as AWS will generate a random name for us.
1
2
3
4
5
6
7
8
9
10
11
echo "== deploy S3 bucket via CFN"
STACK_NAME="cfn-S3-simple"
# --no-execute-changeset makes it so
# that you have to manually accept the hangesets
aws cloudformation deploy \
--template-file template.yml \
--no-execute-changeset \
--region us-east-1 \
--stack-name $STACK_NAME
S3 Terraform
- This is a tool that can be used for any cloud (powerful)
.tfext- run
terraform initin yourtfdir. It will create a folder.terraform - run
terraform planto deploy your infrastructure - run
terraform destroyto delete stack - Look up
terraform gitignoreand copy that file so you do not commit everything
Note: Nothing will appear in
cloudformationbecause this is throughterraform. Just remember to keep your.tfstatefile
1
2
3
4
5
6
7
8
9
10
11
12
13
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.26.0"
}
}
}
provider "aws" {
# Configuration options
re
}
S3 CDK
cdkcloud development kit- to init
cdk init sample-app --language=typescript. Pick whatever language supported cdk bootstrapthis createsCDKToolkitstack (you can see it oncloudformation)cdk deploythis will deploy your stack
1
2
3
4
5
6
7
8
9
10
import { Stack, StackProps } from 'aws-cdk-lib';
import * as s3 from 'aws-cdk-lib/aws-s3';
import { Construct } from 'constructs';
export class CdkStack extends Stack {
constructor(scope: Construct, id: string, props?: StackProps) {
super(scope, id, props);
const bucket = new s3.Bucket(this, 'myBucket');
}
}
S3 Pulumi
- Open source, multi cloud _ Ref https://www.pulumi.com/docs/clouds/aws/
- to install,
curl -fsSl https://get.pulumi.com | sh pulumi new aws-pythonminimal AWS python programpulumi upfor initial deployment
Opentofu
AWS API

- No one really sends http requests to AWS API, so use CLI or SDK etc
AWS CLI
- terminal (text only I/O interface)
- console (physical computer to input info into terminal)
- shell (Bash, zsh, fish, powershell)
- AWS CLI is written using python
Access Keys
- required to have for programmatic access to AWS resources when interacting with AWS API outside the
Management Console - AWS Credentials (treat them both as sensitive)
- Key, not technically sensitive
- Secret, sensitive
- Never share them; never commit them
- You can only have
2access keys - You can deactivate access keys
- Access Keys have whatever access a user has to AWS resources
- Type
aws configureor use env variables
1
2
aws_access_key_id=<id>
aws_secret-access_key=<key>
API Retries and Exponential Backoff
- it is common for networking issues to occur
- (DNS servers, switches, load balancers) all can fail
exponential backoff: try again in 1, 2, 4, 8, 16, 32 seconds (2^x) …- already built in by default
Smithy
- open-source Interface Definition Language (IDL) for defining services and SDKs.
Security Token Service (STS)
Ref: https://github.com/ExamProCo/AWS-Examples/tree/main/api/sts
- enables you to request temporary limited-privilege credentials for IAM or federated users.
- global service, all requests hit a single endpoint
sts.amazonaws.com - you can use it to do
assume_role,get_caller_identity… etc - good practice to use this to hand out short-lived credentials
- assumed roles will have a
aws_session_token
1
2
aws iam create-user --user-name sts-machine-user
aws iam create-access-key --user-name sts-machine-user --output table
1
2
3
4
5
6
7
8
9
aws iam put-user-policy \
--user-name sts-machine-user \
--policy-name StsAssumePolicy \
--policy-document file://policy.json
aws sts assume-role \
--role-arn arn:aws:iam::982383527471:role/my-sts-fun-stack-StsRole-UBQlCIzagA7n \
--role-session-name s3-sts-fun \
--profile sts
Signing API requests
- sign requests so AWS identifies who sent them (SDK and CLI automatically sign for you)
- signatures (1) prevent data tampering (2) verifies identity
- some requests dont need to be signed (public s3 buckets, some STS operation e.g. AssumeRoleWithWebIdentity)
- Versions:
- AWS Signature Version 2: legacy
- AWS Signature Version 4: active
IP Address ranges
- https://ip-ranges.amazonaws.com/ip-ranges.json
- use case:
Curlthe link, runjqand parse the json for some region1 2
curl https://ip-ranges.amazonaws.com/ip-ranges.json \ | jq '.prefixs[] | select(.region=="ca-central-1") | select(.service=="CODEBUILD") | .ip_prefix'
Service Endpoints
- to connet to AWS service programmatically, we use an
endpoint(URL of the entry point). - general format:
protocol://service-code.region-code.amazonaws.com - example:
https://cloudformation.us-east-1.amazonaws.com - generally TLS2 or TLS3.
- Types:
- Global Endpoints : Services that use the same endpoints
- Regional Endpoints: must specify a region
- FIPS: method for using cryptographic keys that use envelope encryption (support FIPS for enterprise)
- Dualstack endpoints: ipv4 and ipv6 support
- above types can be combined
CLI Input Flag
- check commands for support of
--cli-input-jsonor--cli-input-yaml
Configuration Files
https://docs.aws.amazon.com/cli/v1/userguide/cli-configure-files.html
- TOML (Tom’s Obvious, Minimal Language) format
~/.aws/credentialsfor storing sensitive data~/.aws/configused for generic onfiguration- you can store everything in either files, but
credentialstakes precedence - options to configure (most important 4):
aws_access_key_idaws_secret_access_keyregionoutput
Named Progiles
- AWS config files support ability to have multiple profiles (faster switching between profiles)
- if no profile flag
--profileorexport AWS_PROFILE="prod", default is used. aws configure --profile dev
1
2
3
4
5
6
7
8
9
10
11
[default]
aws_access_key_id=
aws_secret_access_key=
[dev]
aws_access_key_id=
aws_secret_access_key=
[prod]
aws_access_key_id=
aws_secret_access_key=
CLI - env vars
- priority: CLI params > env vars > config files
- AWS_CA_BUNDLE - certs bundle to use for https validation
- AWS_CLI_AUTO_PROMPT - enables auto-prompt for AWS CLI v2
- AWS Completer (legacy), AWS Shell (defunct proj)
- features: fuzzy search, command completion, parameter completion … etc
- set
=on-partial(recommended) or=on - hit
ctrl+Rto go to previous command
- AWS_CLI_FILE_ENCODING - the encoding used for text files
- AWS_CONFIG_FILE - path to config file with default
~/.aws/config - AWS_DATA_PATH - list of additional dirs to check outside of the built-in
- AWS_DEFAULT_OUTPUT - overrides the value for the profile setting output (txt, json, table)
- AWS_ROLE_ARN - Amazon Resource Name (ARN) of an IAM role
- AWS_ROLE_SESSION_NAME - the name attached to the role session
- AWS_SESSION_TOKEN - session token value
- AWS_SHARED_CREDENTIALS_FILE - path to
~/.aws/credentials - AWS_WEB_IDENTITY_TOKEN_FILE - path to file that contains an OAuth 2.0 access
- AWS_EC2_METADATA_DISABLED - disables use of EC2 instance metadata service
- AWS_METADATA_SERVICE_NUM_ATTEMPTS - num of attempts to retrieve credentials on an EC2 instance
- AWS_METADATA_SERVICE_TIMEOUT - instance metadata service timeout
- AWS_MAX_ATTEMPTS - value of max retry attempts
- AWS_PAGER - pagination used for output
- AWS_RETRY_MODE - retry mode AWS CLI uses
VPC
- logically isolated virtual network
- all vpc CLI commands are under
aws ec2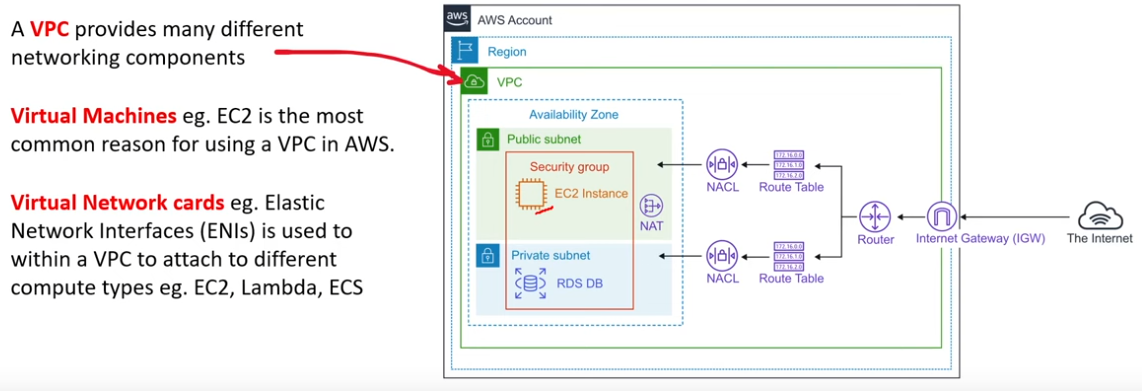
Core Components
- Internet Gateway (IGW)
- Connects your VPC out to the internet
- Virtual Private Gateway (VPN Gateway)
- Connects your VPC to a private external network
- Route Tables (RTs)
- determines where to route traffic within a VPC
- NAT Gateway
- Allows private instances (e.g. VMs) to connect to services outside the VPC
- IPv4 only, no need for network addressing for IPv6
- Network Access Control Lists (NACLs)
- Acts as a
stateless(allow/deny rules) virtual firewall for compute within a VPC - Operates at the subnet level
- default created with every VPC
- Rules:
- Inbound (ingress traffic)
- Outbound (egress traffic)
- One Subnet must be associated with exactly one NACLs
- PRO: block a single IP address
- Rule Number: determines order of evaluation/priority (0 –> 32766); typically use increments of 10 or 100
- Acts as a
- Security Groups (SG)
- Acts as a
stateful(only allow rules) virtual firewall for computer within a VPC - Operates at the instance level
- Acts as a
- Public Subnets
- Subnets allow instance to have public IP addresses
- Private Subnets
- Subnets that diallow instances to have public IP addresses
- VPC Endpoints
- privately connect to AWS support services
- VPC Peering
- connecting VPCs to other VPCs
Key Features:
- Region specific; each region comes with a default VPC
- Up to 5 VPCs per region (adjustable)
- you may connect VPCs across regions using VPC Peering.
- Up to 200 subnets per VPC
- Up to 5 IPv4 CIDR Blocks per VPC (adjustable to 50)
- Up to 5 IPv6 CIDR Blocks per VPC (adjustable to 50)
- Most components cost nothing:
- VPCs, RTs, NACLs, IGWs, SGs, Subnets, VPC Peering (going across regions), IPv6 ddresses
- Some things cost money:
- VPC Endpoints, VPN Gateway, Customer Gateway
- IPv4 addresses, Elastic IPs
- DNS hostnames
CLI
Basics: https://github.com/ExamProCo/AWS-Examples/tree/main/vpc/basics
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
#!/usr/bin/env bash
set -e
# Create our vpc
VPC_ID=$(aws ec2 create-vpc \
--cidr-block "172.1.0.0/16" \
--tag-specifications 'ResourceType=vpc,Tags=[{Key=Name,Value=my-vpc-3}]' \
--region ca-central-1 \
--query Vpc.VpcId \
--output text)
echo "VPC_ID: $VPC_ID"
# Turn on DNS Hostnames
aws ec2 modify-vpc-attribute --vpc-id $VPC_ID --enable-dns-hostnames "{\"Value\":true}"
# create an IGW
IGW_ID=$(aws ec2 create-internet-gateway \
--query InternetGateway.InternetGatewayId \
--output text
)
echo "IGW_ID: $IGW_ID"
# attach an IGW
aws ec2 attach-internet-gateway --internet-gateway-id $IGW_ID --vpc-id $VPC_ID
# create a new subnet
SUBNET_ID=$(aws ec2 create-subnet \
--vpc-id $VPC_ID \
--cidr-block 172.1.0.0/20 \
--query Subnet.SubnetId \
--output text)
echo "SUBNET_ID: $SUBNET_ID"
## auto assign IPv4 addresses
aws ec2 modify-subnet-attribute --subnet-id $SUBNET_ID --map-public-ip-on-launch
# explicitly associate subnet
RT_ID=$(aws ec2 describe-route-tables \
--filters "Name=vpc-id,Values=$VPC_ID" "Name=association.main,Values=true" \
--query "RouteTables[].RouteTableId[]" \
--output text)
echo "RT_ID: $RT_ID"
ASSOC_ID=$(aws ec2 associate-route-table \
--route-table-id $RT_ID \
--subnet-id $SUBNET_ID \
--query AssociationId \
--output text)
echo "ASSOC_ID: $ASSOC_ID"
# add a route for our RT to our IGW
aws ec2 create-route \
--route-table-id $RT_ID \
--destination-cidr-block 0.0.0.0/0 \
--gateway-id $IGW_ID
# Print out delete command
echo "./delete_vpc $VPC_ID $IGW_ID $SUBNET_ID $ASSOC_ID $RT_ID"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
#!/usr/bin/env bash
# VPC IGW SUBNET RT
# Check if the argument is not provided
if [ -z "$1" ]; then
echo "Argument not provided."
else
export VPC_ID="$1"
fi
if [ -z "$2" ]; then
echo "Argument not provided."
else
export IGW_ID="$2"
fi
if [ -z "$3" ]; then
echo "Argument not provided."
else
export SUBNET_ID="$3"
fi
if [ -z "$4" ]; then
echo "Argument not provided."
else
export ASSOC_ID="$4"
fi
if [ -z "$5" ]; then
echo "Argument not provided."
else
export RT_ID="$5"
fi
# detach the IGW
aws ec2 detach-internet-gateway --internet-gateway-id $IGW_ID --vpc-id $VPC_ID
# delete the IGW
# dissaociate subnet
aws ec2 disassociate-route-table --association-id $ASSOC_ID
# delete subnet
aws ec2 delete-subnet --subnet-id $SUBNET_ID
# delete route table
# aws ec2 delete-route-table --route-table-id $RT_ID
# delete vpc
aws ec2 delete-vpc --vpc-id $VPC_ID
(The) Default VPC
- One and ONLY one default VPC exists per each region
- CIDR
172.31.0.0/16~>65,536IPv4 addresses (some are reserved) /20~>4,096IPv4 address per subnet for each possible Availability Zone (AZ)- default SG, default NACL, default DHCP (never need to mess with this guy), RTs, IGW
- can be deleted but you really shouldn’t
- If accidently deleted, you can run
aws ec2 create-default-vpc --region <region> - you cannot mark an existing VPC as default; you can’t restore a deleted default VPC
Deleting a VPC
- Must delete SG, ACL, subnets, RTs, IGWs, eIGWs… first
- then delete VPC
- Otherwise, use console. It will delete things for you.
Default Route / Catch-All-Route
- IPv4
0.0.0.0/0 - IPv6
::/0(:: ~> 0000:0000:0000:0000:0000:0000:0000:0000)
Shared VPCs
- AWS Resource Access Manager (RAM) allows you to share resources across your AWS accounts.
- Must enable
aws ram enable-sharing-with-aws-organization - Allows you to share VPCs (subnets) with other AWS Accounts within the same account to centrally manage resources in a single VPC.
- PROS: (1) Reduce the number of VPCs you manage (2) separate accounts for billing and access control
- You can only share non-default subnets
- You need to create a resource share in RAM (what you are sharing)
- ++ and create a shared principle in RAM (who you are sharing with)
Elastic IPs
- static IPv4 addresses
- can be attached to EC2 or ENI …
- use case: restarting EC2 instances changes IP address. If you rely on an IP then you need ELastic IPs.
- region specific; drawn from Amazon’s pool of IPv4 address
- $1 for each allocated and unassociated IP (incentivsing use or returning)
- IPv6 are ALREADY globally unique, thus Elastic IPs does not apply.
- all AWS services support IPv4; Not all services have IPv6 TURNED ON by default (may requrie extra work)
IPv4 ==> IPv6 (migratio guideline)
- add new IPv6 CIDR block to VPC
- create or associate IPv6 subnets (IPv4 subnets cannot be migrated)
- Update Route Table for IPv6 to IGW
- Upgrade SG rules to include IPv6 address ranges
- Migrate EC2 instance type if it does not support IPv6
AWS Direct Connect
- enterprise solution
- connect from on-premisses locations to AWS
- helps reduce network costs and increase bandwidth throughput
- provides a more consistent network experience than typical internet-based connection
- Two very-fast options:
- Lower Bandwidth: 50MBps, 500 MBps
- Higher Bandwidth: 1GBps, 10GBps, 100GBps



AWS VPC Endpoints
- privately connect VPC to other AWS services
- eliminates the need for IGW, NAT, VPC connection, AWS Direct Connect
- Instances in the VPC do not require a public IPv4 address
- Traffic does not leave AWS network
- Horizontally scaled, redundant, and highly available
- Allows for secure communication
- 3 types:
- Interface Endpoints
- Elastic Network Interfaces (ENI) w/ a private IP address
- serve as an entry points for traffic to a supported service
- allows you to access servics on AWS easily and securely by keeping your traffic inside the AWS network
- NOT free; avoid; for the most part it is for enterprise 2. Gateway Endpoints
- provide reliable connectivity to S3 and Dynamo (just these two) w/o requiring an IG or NAT
- no additional charge; secure; great 3. Gateway Load Balancer Endpoint (GWLB)
- powered via PrivateLink under the hood;
- allows you to dist traffic to a fleet of network virtual appliances
- basically allows you to filter your traffic more by using security appliances
- Firewalls, Intrusion Detection/Prevention Systems IDS/IPS, Deep Packet Inspection Systems
- you will have to route traffic to it using RTs
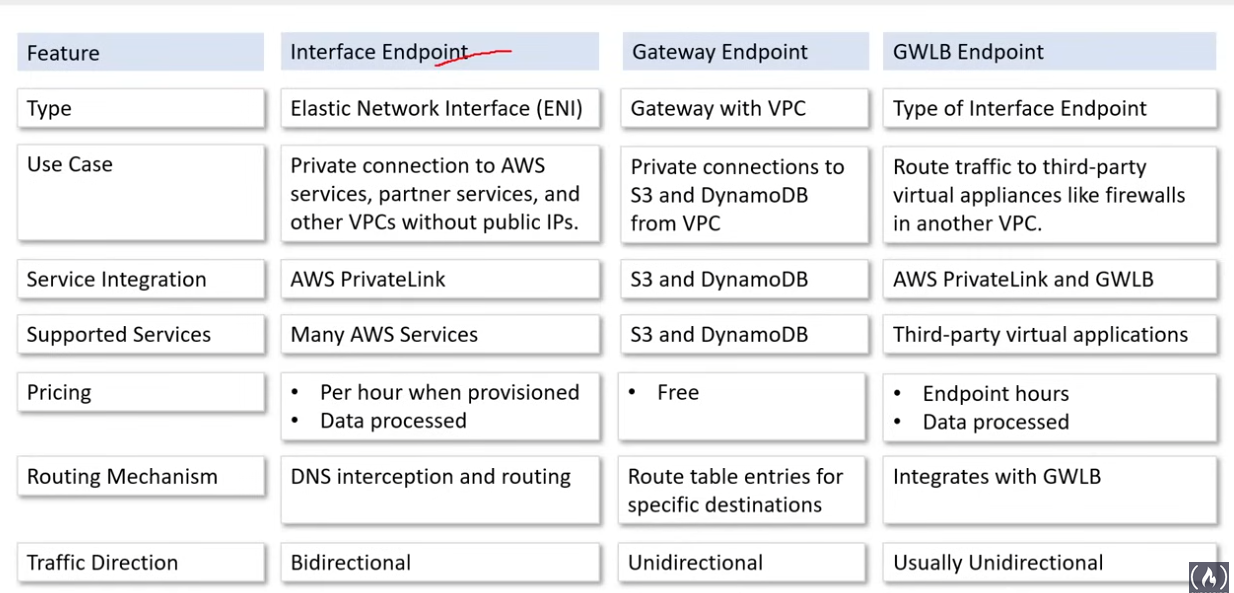
Private Link
- broader service that allows you to securely connect your VPC to other services in your account or other accounts or supported marketplace partners… w/o need for IGW, NAT, VPN, AWS Direct Connect
VPC Flow Logs
- capture IP traffic information
- has to be turned on the VPC level
- can be scoped to VPC, subnets, TG, …
- can monitor traffic for ACCEPT, REJECT, ALL
- logs can be delivered to S3, CloudWatch, Kinesis Data Firehose
- example:
<version> <account-id> <interface-id> <srcaddr> <dstaddr> <scrport> <dstport> <protocol> <packets> <bytes> <start> <end> <action> <log-status>
AWS VPN
- AWS Site-2-Site VPN (connect on-prem network to VPC)
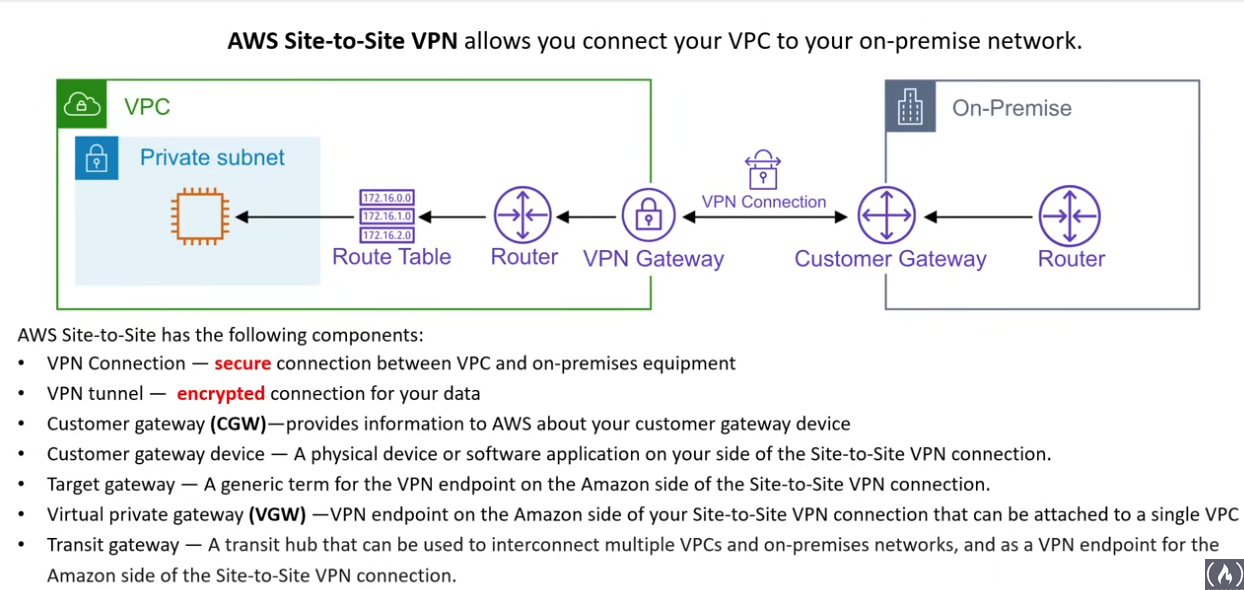

- AWS client VPN (connect users to AWS or on-prem networks)
- IPsec is used here.
- Direct Connect is private by not secure. You can use this service with it.
Virtual Private Gateway (VGW)
- VPN endpoints on the AWS side of you Site-2-Site VPN that can be connected to a single VPC
- assign it an Autonomous System Number (ASN) or leave it with default 64512
- ASN cannot be changed
- ASN is a unique identifier that is globally allocated to each AS that participates in the internet
Customer Gateway (CGW)
- resource that represents the customer gateway device in your on-prem network
Tranasit Gateway (TGW)
- leverages AWS Resource Manager (RAM)
- is a transit hub that you can use to interconnect your VPCs and your on-prem network
- supports IPv4 and IPv6
- up to 5000 VPCs per gateway (ENIs provisioned for each VPC)
- each attachment can handle up to 50Gbits/second
- works with Direct Connect, VPN, 3rd party virtual appliances
AWS Client VPN
- fully managed client-based VPN service
- connects you to a Client VPN endpoint
- all the usual features of a secure vpn
- use case: connect to an RDS instance in a private subnet
Network Address Translation (NAT)
- A method of mapping an IP address from one space to another by modifying the information in the IP header of packets while they are in transit
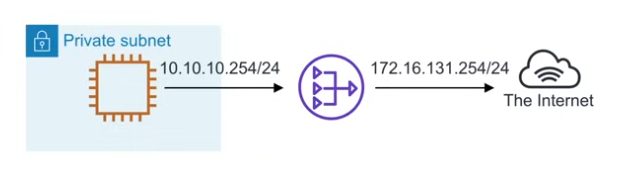
- Only for IPv4. Not applicable for IPv6.
NAT Gateway
- replaced NAT Instances, which did the same thing but sat in an EC2
- fully managed NAT service
- allows your instances in your private subnet to establish outbound connections
- 1 per subnet
- can get expensive very quickly
- 2 modes:
- Public
- instances in private subnets can connect to the internet through a public NAT gateway
- cannot receive unsolicited inbound connection from internet
- must be associated to an Elastic IP 2. Private
- instances in private subnets can connect to other VPCs or on-prem network through private NAT gateway
- cannot associate an elastic IP address with this type
- DNS64 and NAT64

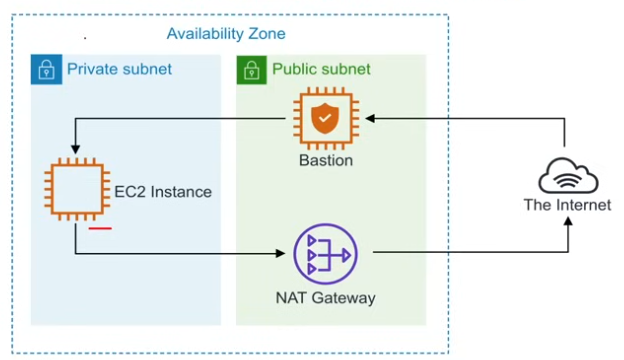
Bastion / Jumpbox
- security hardened VMs (EC2 instances) that provide secure access to private subnets
- access private subnet via SSH or RCP
- jumpboxes because you are jumping from one box to another
- bastions since it is something that gives protection against attack
- NATs should/can NOT be used as Bastions
- System Manager’s Session Manager can replace the need for Bastions, unless with niche cases
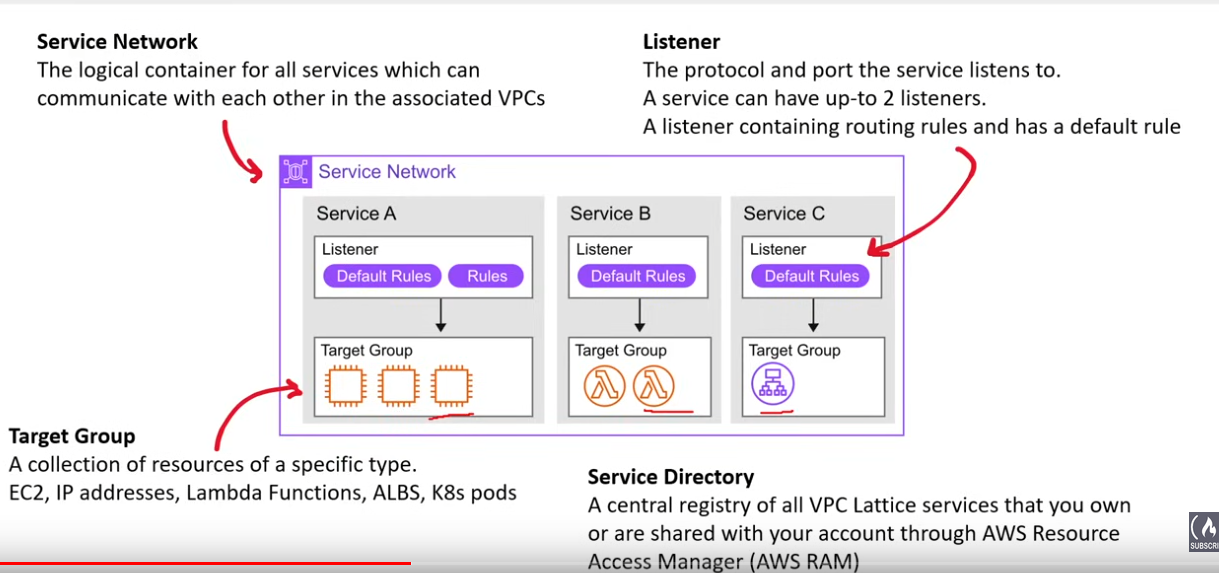
VPC Lattice
- easily turn your AWS resources into services for a micro-services architecture
- can be used in a single/ across multiple VPCs; across accounts; performs NAT to IPv4 and IPv6
- integrates with IAM
- Weight routing for traffic (e.g. blue/green or canary style)
- …
Traffic Mirroring
- can be used to send a copy of your traffic to a security monitoring appliance
- attaches a VXLAN header
- you need mirror source, mirror target, and mirror filter
AWS Network Firewall
- stateful managed netwrk firewall and IDS/IPS for VPCs
- uses SURICATA under the hood
- filter IGW, NAT, VPN, Direct connect traffic
- use cases:
- pass traffic only from know AWS domains or IPs
- custom list of known bad domains to limit
- deep packet inspection
VPC Peering
- connect one VPC to another
- works with IPv4 and IPv6
- peering uses Star Configuration: 1 Central VPC – 4 Other VPCs
- no overlapping CIDR
- 4 steps
aws ec2:create-vpc-peering-connectionaccept-vpc-peering-connectioncreate-route(on accepter and requester)- ensure SG are configured properly;
describe-group-references
Network Address Usage
- helps ensure you do not run out of room in your VPC
- mostly for enterprise

IAM
- manage AWS users and groups to allow and deny their access to AWS resources
IAM Policies
- JSON docs which grant permissions for a specific user, group, or role to access servicces. Policies are attached to IAM identities.
- a policy can have to up 5 versions !! (
create-policy-versionanddelete-policy-version) - Types:
- Managed
- Policies created and managed by AWS. Labaled with orange box. Cannot edit those. 2. Customer
- You create those. Have no symbol. You can edit those. 3. Inline
- Directly attached to a particular role/user. cannot be re-used.

Principle of Least Privilege (PoLP)
- computer security concept of providing the least amount of permissions to perform an action
- Just-Enough-Access (JEA): permitting only the exact actions for the identity to perform a task
- Just-In-Time: Permitting the smallest length of duration an identity can user permissions
- ConsoleMe: https://github.com/Netflix/consoleme
- Risk-based adaptive policies: each attempt to access a resource generates a risk score of how likely the request is to be from a compromised source. The risk could be calculated based on many factors (e.g. device, IP, location, MFA, …)
IAM Permissions
- The API actions that can or cannot be performed. They are represented in the IAM policy
IAM User
- End users who log into the console or interact with AWS resources programmatically or via click ops
IAM Groups
- Group up your Users so they all share permission levels of the group (e.g. Admins, devs …)
IAM Roles
- Grant AWS resources perimssions to specific AWS API actions. Associate policies to a role then assign it to an AWS resource.
AWS Root User
- special user created at time pf AWS account creation
- uses email and password to log in (regular users has to provide account id, username, and password)
- root user cannot be deleted
- root user has full permission, cannot be limited (even with iam polices)
- can be limtied using AWS organizational service control
- there can only be one Root user per account
- should not be used for daily tasks
- strongly recommended to turn on MFA and never use Access Keys
- you can use it for
- change account setting, close aws account, change aws support plan
- enable MFA delete on s3 bucket …
- sign up for GovCloud
IAM Password polices
- This is under Account Setting (probably)
- set minimum requirements of a password and rotate passwords sop user s havbe to update their passwords after X days.
Access Keys
- users with programmatic access can have up to 2
access keys
MFA
- use a second device to confirm that it is you logging in
Temporary Security Credentials
- just like
Access KeysBUT they are temporary - useful in scenarios that involve: identity federation, delegation, cross-account access …
- they can last from minutes to an hour
- they are not store with the user but are generated dynamically and provided to the user when requested.
- these are the BASIS for roles and identity federation (you are using this w/o knowing it)
- AWS automatically generates those for IAM Roles
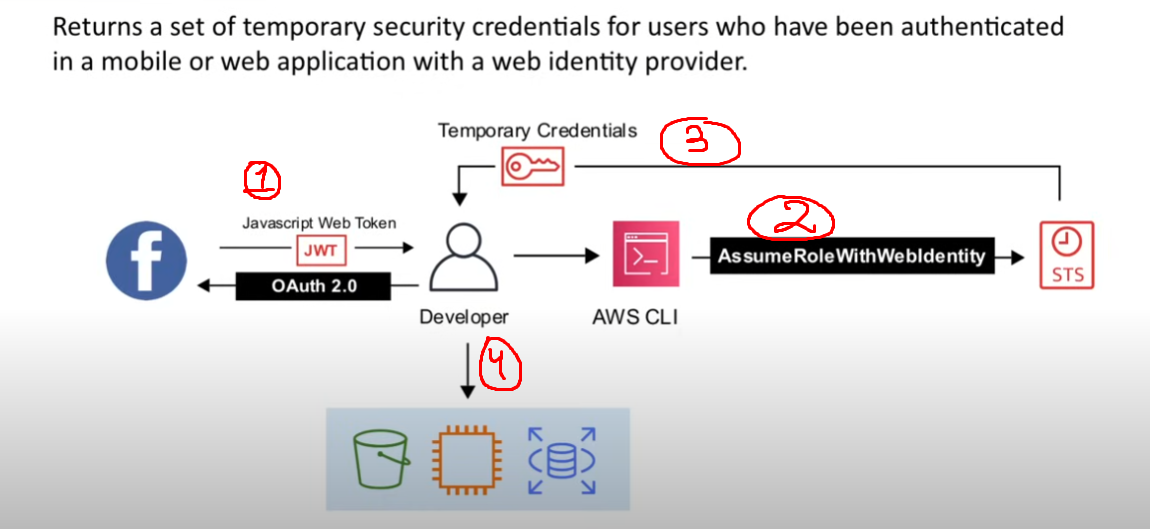
identity federation
- linked identities across platforms
- IAM supports two types of identity federation:
- Enterprise identity federation
- SAML (Microsoft AD)
- Custom Federation broker 2. Web identity federation
- Amazon, Facebook, Google, OpenID Connect 2.0 (OICD)
- Amazon, Facbook and Google federations adhere to the
OICDprotocol which in turn is built onOAuth 2.0authorization framework
Security Token Service (STS)
- enables you to request temporary limited-privilege credentials for IAM users or for federated users
aws sts(common actions:AssumeRole,AssumeRoleWithIdentity)- you can go to account setting and deactivate this for certain regions (!)
Cross-Account Role
sts:AssumeRoleaction to a particular IAM Role.- That way they do not have to make a new user account in the AWS env
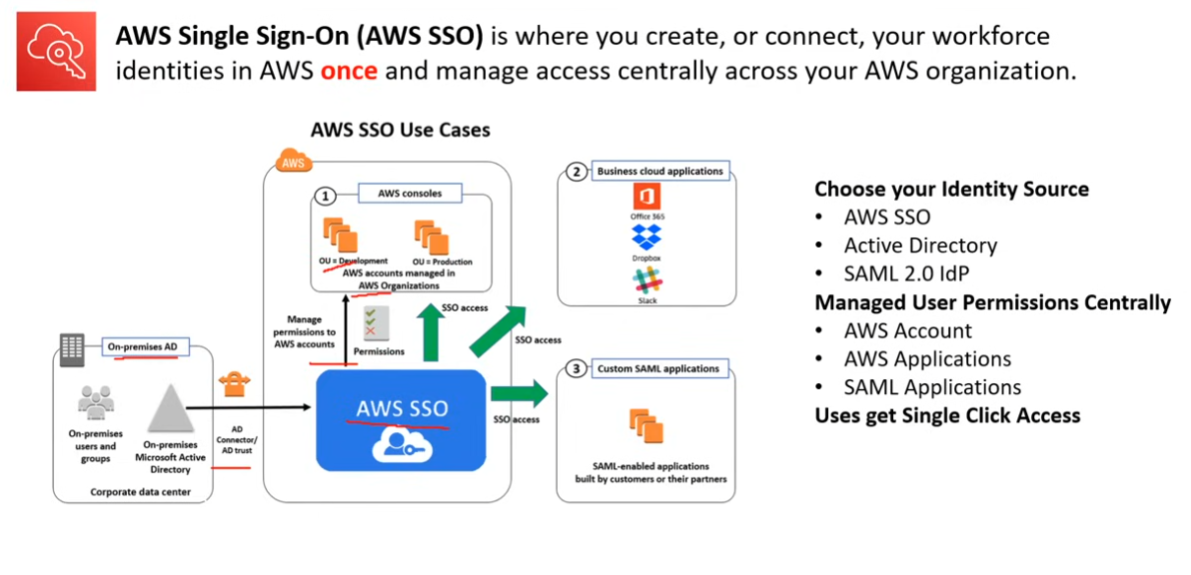
SSO
EC2
- highly configurable virtual server
- OS:
RedHat,ubuntu,windows,Amazon Linus,SUSE… - Instance Type:
t2.nano,C4.8xlarge… - Storage:
SSD,HDD,Virtual Magnetic Tape,Multiple Volumes… - Configuration:
Security Groups,Key pairs,UserData,IAM roles…
- OS:
- takes minutes to launch
- anything and eveyrhting on AWS uses EC2 under the hood
- For interactive diagnostics, > session manager > then type
sudo su - ec2-user
Cloud Init
- Ref:
- industry standard multi-distribution method for cross-platform cloud instance initialization.
- cloud instances are initialized from a disk image and instance data:
- meta-data, user-data (script you wanna run when an instance first boots up – e.g. Apache web server), vendor-data
- AWS EC2 supports cloud init
User Data
- provide a script ti EC2 UserData to have Cloud Init automatically run on first boot
- This can be a
bash scriptor acloud config yaml file - scripts MUST be
base64when using the API. The AWS CLI and Console will automatically encode tobase64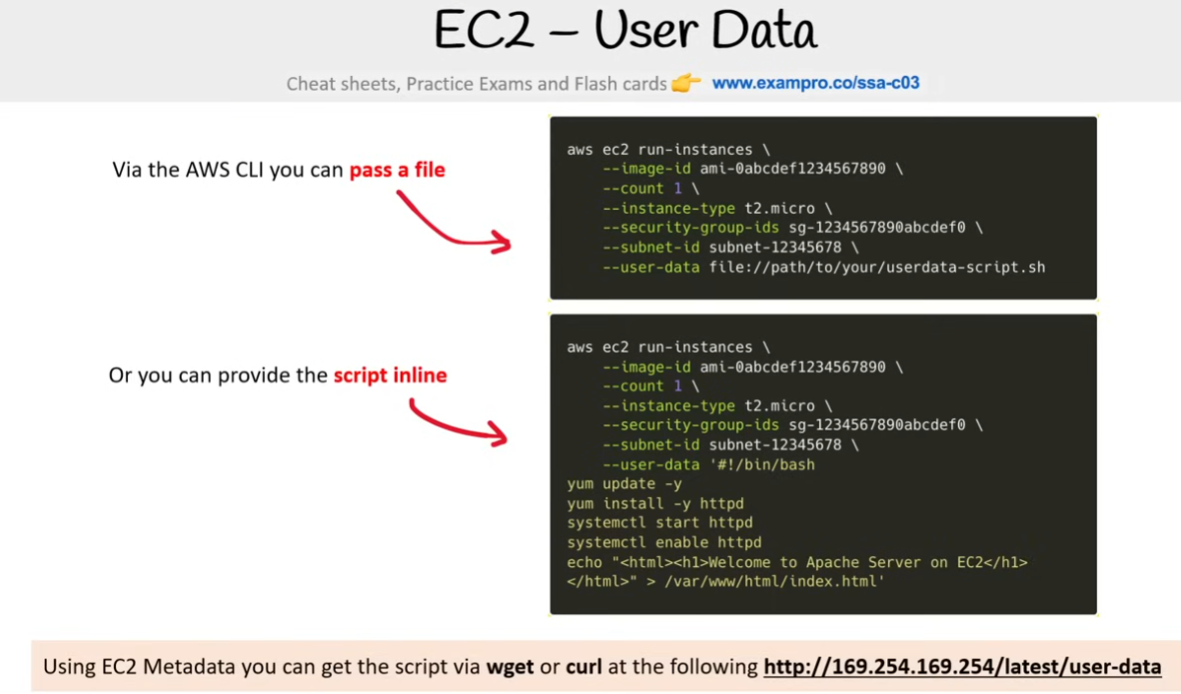
Meta Data (MDS)
- two versions:
- Instance Metadata Service Version 1 (IMDSv1) – a request/response method
- Instance Metadata Service Version 2 (IMDSv2) – a session-oriented method
- IMDSv2 was developed due to an exploit in IMDSv1
- by default, IMDSv2 is active (
--http-tokens required) - endpoints: IPv4
http://169.254.169.254/latest/meta-data/IPv6http://[fd00:ec2::254]/latest/meta-data/ - IMDSv1:
curl <endpoint> - IMDSV2:
1 2
TOKEN=`curl -X PUT "http://169.254.169.254/latest/api/token" -H "X-aws-ec2-metadata-token-ttl-seconds: 21600"` \ && curl -H "X-aws-ec2-metadata-token: $TOKEN" -v endpoint
- This endpoint has 60+ categories
http://169.254.169.254/latest/meta-data/<some_categories_here>- e.g.
security-groups
Instance Types
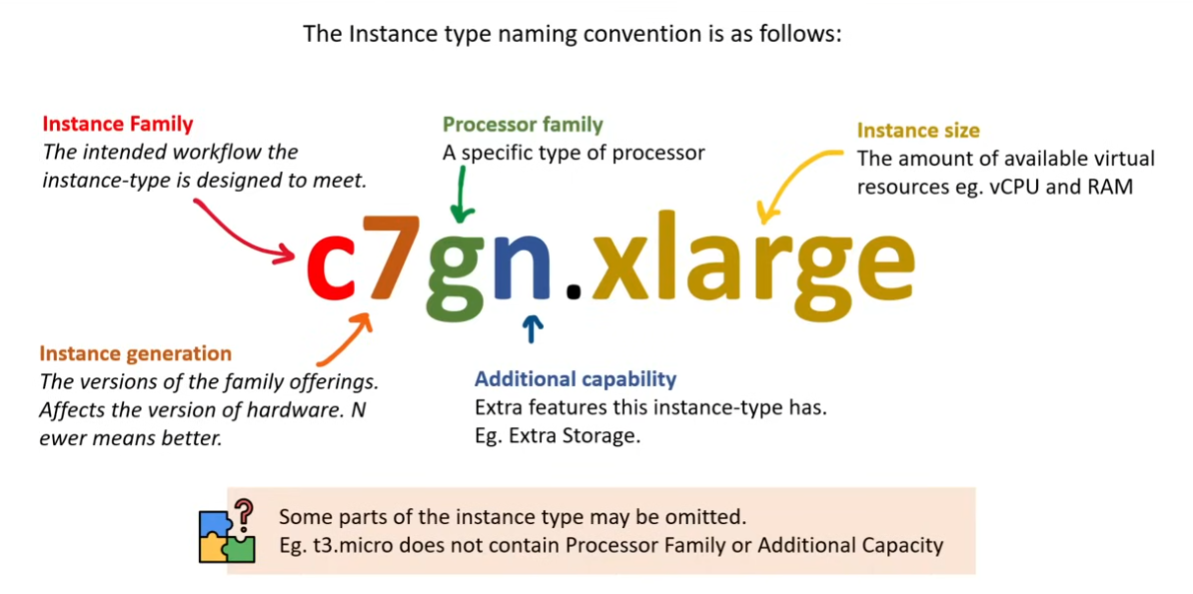
Instance Families
- different combinations of CPU, Memory, Storage, and networking capacity
- Types:
General Purpose: balance of compute, memory, and networking resources- examples: A1, T2, T3, T3a, M4, M5, M5a, M5n, M6zn, M6g, M6i, Mac
Compute Optimized: ideal for compute bound applications like scientific modeling and dedicated gaming servers- examples: C5, C4, Cba, C5n, C6g, C6gn
Memory Optimized: for processing large data sets in memory (e.g. in memory databases or real time big data analytics)- examples: R4, R5, R5a, F5b, F5n, X1, X1e, High Memory, z1d
Accelerated Optimized: hardware accelerators for machine learning, speech recognition, or computaional finance- examples: P2, P3, P4, G3, G4ad, G4dn, F1, Inf1, Vt1
Storage Optimized: high sequential read/write access to very large data sets on local storage- examples: I3, I3en, D2, D3, D3en, H1
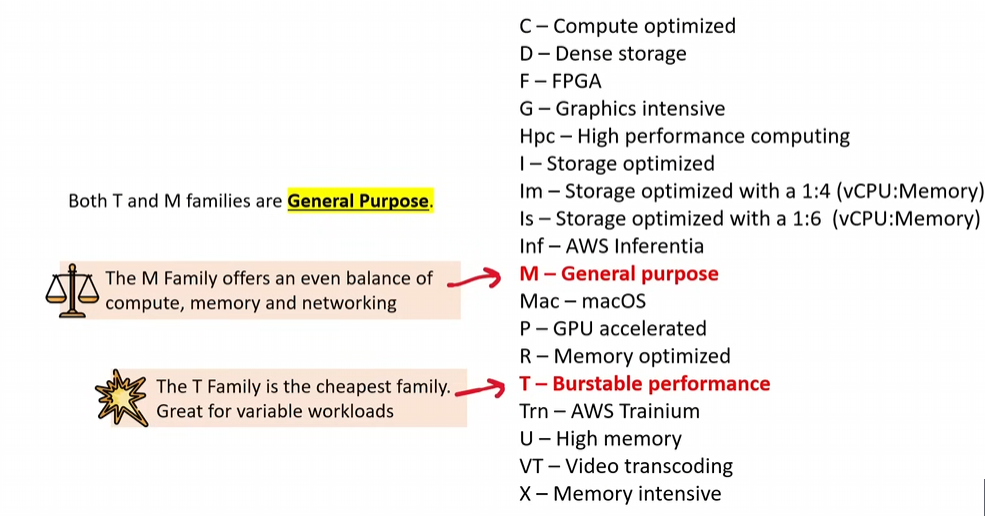
- examples: I3, I3en, D2, D3, D3en, H1
Processors

Instance Lifecycle
- Actions:
Launch– create and start EC2 instanceStop– Turn off but not deleteStart– Turn on a previously stopped instanceTerminate– Delete instanceReboot– performs a soft rebootRetire– notifies when instance is scheduyled for retirementRecover– Automatically recovers a failed instance on new hardware if enabled
- States:
Pending– preparing to enterrunningstates. This can be when the instance is first launched or started after being in thestoppedstate.Running– instance is ready to useStopping– preparing to be stoppedStopped– instance is shut down and cannot be used. Can be started at any time.Shutting-down– preparing to be terminatedTerminated– permanently deleted
Instance Console Screenshot
aws ec2 get-console-screenshot… just a screenshot of the terminal.- useful when you cant ssh
Hostnames
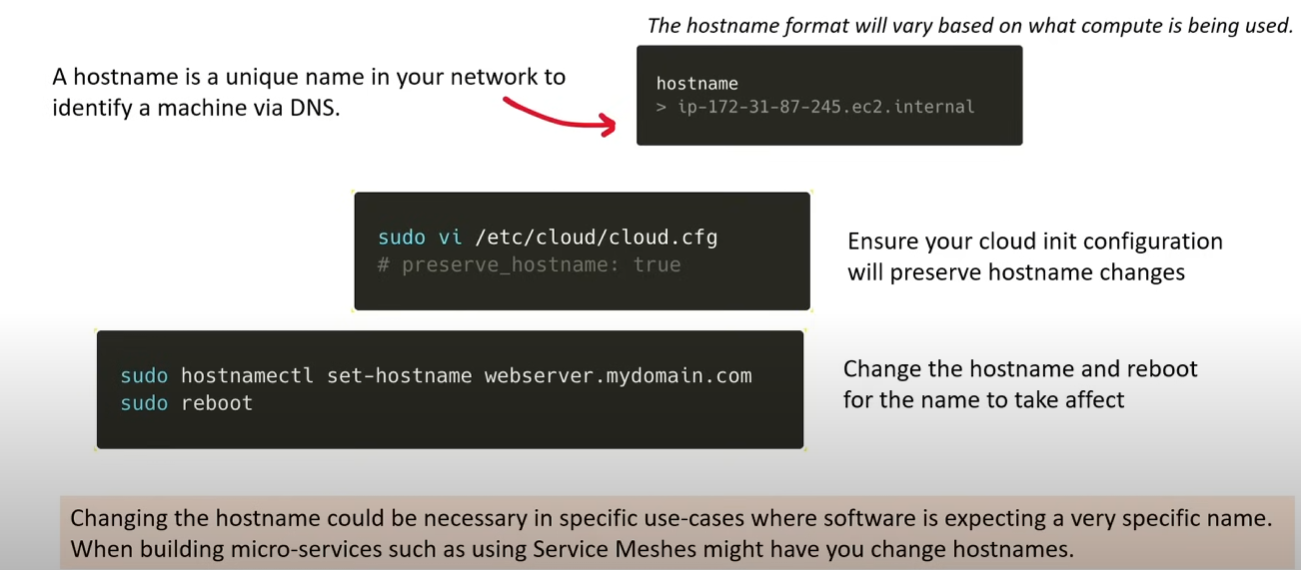

Default User
- run
whoami, if you aressmuserthen you probably wanna runsudo su - ec2-userto switch toec2-useridentity - List of default users:

Burstable Instances
- Burstable instances allow workloads to handle bursts of higher CPU utilizations for very short durations. This saves customers money.
- T2, T3, T3a, T4g …
- 2 modes:
Standard(default)- provides baseline level of CPU performance with the ability to burst above the baseline using accumulated CPU credits; suitable for workloads with variable CPU usage.
Unlimited- Allows an instance to sustain high CPU performance for any period whenever required, exceeding the baseline accumulated CPU credits, with additional charged applied for the extra CPI usage beyond the accumulated credits.
Source and Destination Checks

System Log
- ability to observe the system log through console
- Make sure CloudWatch Unified Agent is running and the instance is permitted to write to CloudWatch Logs.
Placement Groups

Connect
SSH Client- gen pub and private keys on AWS and download public key
- port 22 needs to be open on the Security Group to connect
EC2 instance connect- This is a thing that is installed in EC2 to work.
- short-lived SSH keys controlled by IAM policies. Works only w/ linux and not all instances
Sessions Manager- Connections to Linux/Windows via reverse connection
- no need top open ports; access is controlled via IAM
- supports audit tail of logins
Fleet Manager Remote Desktop- connect to windows machines using RDP
EC2 Serial Console- Established a serial connection giving you direct access for troubleshooting the underlying hardware
- requires instance to be built on the AWS Nitro System
Amazon Linux (AL)
- AWS’s managed Linux dist – based off CentOS and Fedora which in turn is based on Red Hat Linux (RHEL)
- AWS provides better technical support for this guy vs non AWS OS dists
- uses
yumpackage manager anddnfmay be available amazon-linux-extrasis a feature to help you get additional packagessudo amazon-linux-extras install epel -yfor even more stuff
Amazon Machine Image (AMI)
- provides info required to launch an instance.
- You can turn your EC2 instances into AMIs so you can create copies of your services
- Region specific
- help you keep incremental changes to your application
- can be managed using
Systems Manager Automationso that you can routinely patch your AMI - Regions are baked into AMI IDs when you choose your AMI, so watch out what you pick!!
...29dUS EAST 1,...e5cCA Central 1
- Boot Modes:
Legacy BIOSandUnified Extensible Firmware Interface (UEFI) Elastic Network Adapter (ENA): enhanced networking feature – speeds up to 100GbpsRoot Device Type:Amazon EBS-backedstorage is independent of instance (keeps data)instance store-backedstorage is part of the instance (loses data)
- You can create an AMI from an existing EC2 instance that is either running or stopped
aws ec2 create-image --instance-id <ec2_instance_id> --name <name_this_image>
- You can copy an AMI even across to another region. (only way to get an AMI to another region)
aws ec3 copy-image --source-region <source_region> --source-image-id <ami_id> --name <copied_image> --region <new_region> --encrypted
- You can encrypt the storage of a non encrypted AMI during the copy.
- You can store AMI copies in S3 (if you ever need to do this)
- Actions:
Deregisterdont want to allow any news instances to be launched with the AMIDeprecatemark a date when it will not be allowed to useDisableprevents the AMI from being used. Can be reenabled later. (soft delete)
- Sharing:
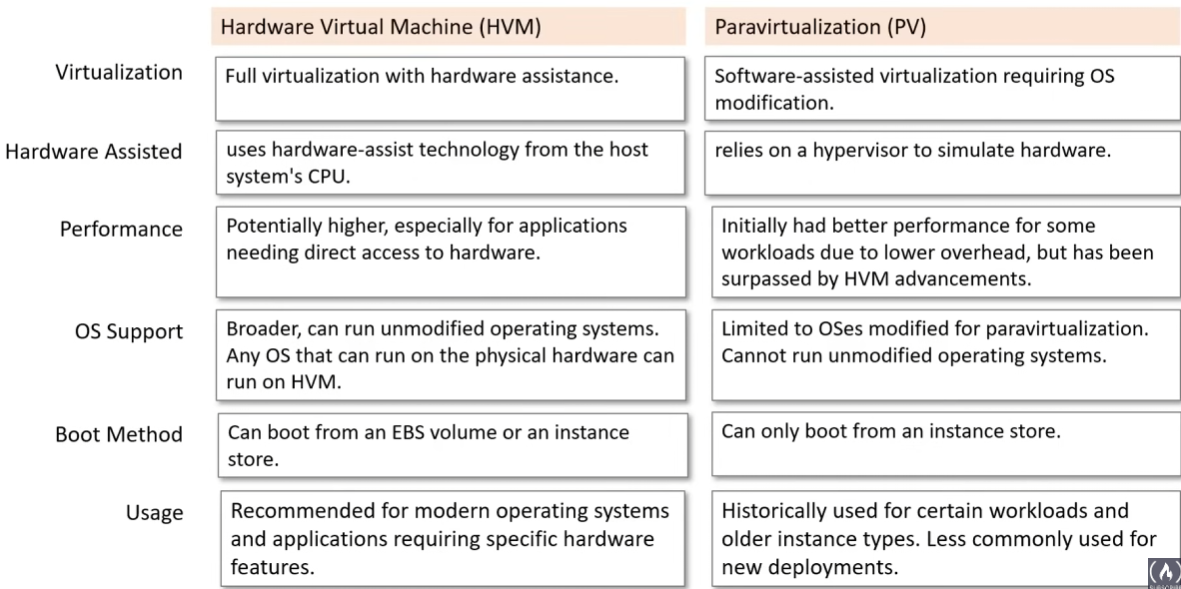
Public,Explicit, orImplicit - Virtualization Types (mostly use HVM):
ASG
- Auto Scaling Groups
- contains a collection of EC2 instances that are treated as a group for the purpose of automatic scaling and management.
- Features:
Capacity Settings– set the expected range of capacityHealth Check Replacements– replace instance if they are determined unhealthy- EC2 or ELB Health Checks
Scaling Policies– set complex rules to determine when to scale up or down- Simple, Step, Target Tracking, or Predictive Scaling
- Supports: EC2, ECS w/ EC2, EKS w/ EC2.
- Does not support Fargate.
- Fargate might be using ASG under the hood since they are managed for customer to scale as need
Capacity Settings
Min Size– how many EC2 instance should at least be runningMax Size– how many EC2 instance are allowed to be runningDesired Capacity– how many EC2 instance should at be ideally running
Health Check Replacement:
- ASG will replace an instance if:
- EC2 instance fails either of its EC2 Status checks
- ELB-based health check. ELB pings an HTTP endpoint at a specific path, port, and status code
ELB integration
- ELB can be attached to your ASG
aws autoscaling attach-load-balancer-target-groups --auto-scaling-group-name <my-asg> --target-group-arns <...>- Classic Load Balancers (CLB) are associate directly to the ASG
- ALB, NLB, GWLB are associated indirectly via their target groups
Dynamic Scaling Policy
- how much ASG should change capacity
- 3 dynamic scaling policies:
Simple Scaling- change capacity in either direction when triggered by CloudWatch Alarms
- if you are going to use this scaling method, then use
--cooldown - but really avoid using it and instead use the other two
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
# Scale Out/up by 30% aws autoscalling put-scaling-policy \ --policy-name <scale-out-policy> \ --auto-scaling-group-name <my-asg> \ --scaling-adjustment 30 \ --adjustment-type PercentChangeInCapacity # Scale in/down 1 instance every 180 seconds aws autoscalling put-scaling-policy \ --policy-name <scale-in-policy> \ --auto-scaling-group-name <> \ --scaling-adjustment -1 \ --adjustment-type ChangeInCapacity \ --cooldown 180 # set up the scale out trigger aws cloudwatch put-metric-alarm \ --alarm-name <> \ --metric-name <> \ --namespace AWS/EC2 \ --statistic Average \ --period 300 \ --threshold 70 \ --comparison-operator GreaterThanThreshold \ --dimensions Name=AutoScalingGroupName,Value=my-asg \ --evaluation-periods 2 \ --alarm-actions <arn-to-scale-out-policy> --unit Percent
Step Tracking- change capacity in either direction when a CloudWatch Alarm is repeatedly triggered
1 2 3 4 5 6 7 8 9 10 11
# scale by 10% between 0 and 15, etc ... aws autoscalling put-scaling-policy \ --policy-name <scale-out-policy> \ --auto-scaling-group-name <my-asg> \ --policy-type StepScaling --adjustment-type PercentChangeInCapacity --metric-aggregation-type Average --step-adjustments MetricIntervalLowerBound=0.0,MetricIntervalUpperBound=15.0,ScalingAdjustments=10 \ MetricIntervalLowerBound=15.0,MetricIntervalUpperBound=25.0,ScalingAdjustments=20 \ MetricIntervalLowerBound=25.0,ScalingAdjustments=30 \ --min-adjustments-magnitude 1
Target Tracking- change capacity in either direction based on metric value
- will create two CloudWatch alarms for you (whereas other ones wont)
- you provide a
config.jsonwith policy
1 2 3 4 5
aws autoscalling put-scaling-policy \ --policy-name <> \ --auto-scaling-group-name <my-asg> \ --policy-type TargetTrackingScaling --target-tracking-configuration file://config.json
1 2 3 4 5 6 7
{ "TargetValue": 50.0, "PredefinedMetricSpecification": { "PredefinedMetricType": "ASGAverageCPUUtilization" } }
Predictive scaling policy- triggers scaling by analyzing historical load data to detect daily or weekly patterns in traffic flow
- you need 24 hour CloudWatch Data before you can create it
- Will continusously use the last 14 days of data to tweak policy
- updates every 6 hours
1 2 3 4 5
aws autoscalling put-scaling-policy \ --policy-name <> \ --auto-scaling-group-name <my-asg> \ --policy-type PredictiveScaling --target-tracking-configuration file://config.json
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
# forecast only { "MetricSpecifications": [{ "TargetValue": 40, "PredefinedMetricPairSpecification": { "PredefinedMetricType": "ASGAverageCPUUtilization" } }], "Mode": "ForecastOnly" } # forecast and scale { "MetricSpecifications": [{ "TargetValue": 40, "PredefinedMetricPairSpecification": { "PredefinedMetricType": "ASGAverageCPUUtilization" } }], "Mode": "ForecastAndScale" }
- determine how capacity should change:
ChangeInCapacity: change capacity based on scaling adjExactCapacity: change capacity to an exact numberPercentChangeInCapacity: change capacity by percentage
Termination Policies

ELB
- Elastic Load Balancer is a suit of load balancers.
- Physical hardware that accepts traffic and distributes the traffic to multiple targets
- Used for EC2, ECS, Fargate, EKS … they are usually tied to a VPC
- Types:
ALB- Application Load Balancer
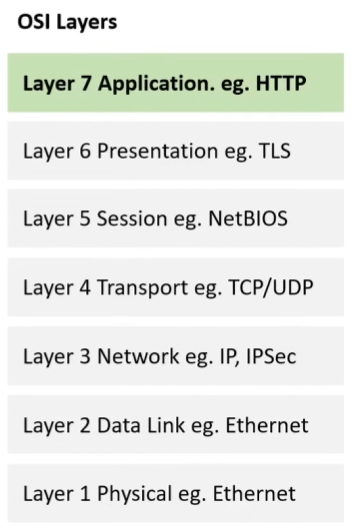
- operates on the OSI layer 7 the application layer (http/https)
- capable of routing based on HTTP information
- can leverage Web Application Firewall (WAF)
NLB- Network Load Balancer
- operates on OSI layer 3/4 TCP/UDP
- designed for large throughput of low-level traffic
GLB- Gateway Load Balancer
- Routes traffic to virtual appliances before traffic reaches its destination
- useful as a security layer for traffic in transit
CLB- Classic Load Balancer
- operates on OSI layer 7 and 3/4
- does not use target groups, directly attach targets
- legacy – most have moved to
ALBorNLB
OSI Layers
Rules of traffic
Listeners– eval any traffic that matches the port (e.g. 443 https or 80 http)Rules(customizable only forALB)- tells listerners what to do with their traffic
- e.g. forwards traffic to target groups
Target Groups- logical grouping of targets such as specific EC2 instances or IPs
CLBattaches directly w/o target groups
ALB
- designed to balance HTTP(S) traffic
- operates at Layer 7 of the OSI model
Request Routingallows you to add routing rules to your listeners based on the HTTP protocol- Supports Websockets and HTTP/2 for real-time, bidirectional communication
- can handle authorization and authentication of HTTP requests
- can only be access via its hostname. If you need a static IP, forward an
NLBtoALB - AWS
WAFcan be placed in front ofALBfor OWASP protection (common attacks protection) - AWS Cert Manager (
ACM) can be attached to listeners Global Acceleratorcan be placed in front of ALB to improve gloval availabilityCloudFrontcan be placed in front of ALB to improve gloval cachingCognitocan be used to authenticate users via HTTP requests- use cases: microservices, e-commerce, web apps, SaaS apps
NLB
- designed to balance TCP/UDP
- operates at layer 4 of the OSI model
- can handle millions of requests/sec while still maintaining extremely low latency
Global Acceleratorcan be placed in front of ALB to improve gloval availability- preserves the client source IP
- when a static IP address is needed for a load balancer
- use cases: high-performance computing, real-time gaming, big data, telecommunication networks, Trading systems
CLB
- legacy
- HTTP or TCP (not at the same time) – layer 7 and 3/4
- not recommended to use since we have better ones
Route 53
- like GoDaddy or nameCheap but AWS
- Domain Name Service (DNS)
- register and manage domains
- implement complex traffic flows
- monitor records
- Resolve VPC’s outside of AWS
- use case: route traffic !!!
Hosted Zones (HZ)
- container for record sets, scorped to route traffic for a specific domain or subdomain
- types:
publicHZ – how you want to route traffic inbound from the internetprivateHZ – how you want to route traffic within a VPC
- example where every user will have their own subdomain:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
Resources:
DomainHZ:
Type: AWS::Route53::HostedZone
Properties:
Name: example.com
SubdomainHZ:
Type: AWS::Route53::HostedZone
Properties:
Name: app.example.com
RecordSet:
Type: AWS::Route53::RecordSet
Properties:
HosterZoneId: !Ref DomainHZ
Name: app.example.com
Type: NS
TTL: '300'
ResourceRecords: !GetAtt SubdomainHZ.NameServers
WildcardRecordSet:
Type: AWS::Route53::RecordSet
Properties:
HosterZoneId: !Ref DomainHZ
Name: *.app.example.com
Type: A
ResourceRecords:
- "app.example.com"
Record Sets
- collection of records which determine where to send traffic
- always change in batch via the API
- Record types:
- A
- AAAA
- CAA
- CNAME
- DS
- MX
- NAPTR
- NS
- PTR
- SOA
- SPF
- SRV
- TXT
- Alias (special)
1
2
3
4
5
6
7
8
9
10
11
12
13
aws route53 change-resource-record-sets \
--hosted-zone-id "Z3AQBST..." \
--change-batch '{"Changes": [{
"Action": "UPSERT",
"ResourceRecordSet": {
"Name": "example.com",
"Type": "A",
"AliasTarget": {
"DNSName": "s3-website-us-east-1.amazoneaws.com",
"HostedZoneId": "Z3AQBS..."
}
}
}]}'

Traffic Flow
- visual editor lets you create sophisticated routing configs
- very expensive
- supports versioning
Routing Polices Overviews
- 7 types:
Simple Routing- default policy
- if you provide multiple records to route traffic to, they will be chosen at random
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
aws route53 change-resource-record-sets \ --hosted-zone-id "Z3AQBST..." \ --change-batch '{"Changes": [{ "Action": "UPSERT", "ResourceRecordSet": { "Name": "www.example.com", "Type": "A", "TTL": 300, "ResourceRecords": [ { "Value": "34.229.79.211"}, { "Value": "14.229.29.21"}, { "Value": "3.209.80.38"}, ] } }]}'
Weighted Routing- weighted values to split traffic
- send % of overall traffic to a paritcular resource
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
aws route53 change-resource-record-sets \ --hosted-zone-id "Z3AQBST..." \ --change-batch '{"Changes": [{ "Action": "UPSERT", "ResourceRecordSet": { "Name": "www.example.com", "Type": "A", "TTL": 300, "WeightedRoutingPolicy": { "WeightedRecords": [ { "Value": "34.229.79.211", "Weight": 10}, { "Value": "14.229.29.21", "Weight": 20}, { "Value": "3.209.80.38", "Weight": 30}, ], "FallbackBehavior": "NON_FAILOVER" } } }]}'
Latency Routing- route to region with lowest latency
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
{ "Changes": [ { "Action": "UPSERT", "ResourceRecordSet": { "Name": "example.com", "Type": "A", "AliasTarget": { "DNSName": "dualstack.blah.us-east-1.amazonaws.com", "EvaluateTargetHealth": false, "HostedZoneId": "ALB_1_HZ_ID" }, "SetIdentifier": "us-east-1", "Region": "us-east-1", "LatencyRoutingPolicy": { "Region": "us-east-1" } } }, { "Action": "UPSERT", "ResourceRecordSet": { "Name": "example.com", "Type": "A", "AliasTarget": { "DNSName": "dualstack.blah2.us-west-1.amazonaws.com", "EvaluateTargetHealth": false, "HostedZoneId": "ALB_2_HZ_ID" }, "SetIdentifier": "us-west-1", "Region": "us-west-1", "LatencyRoutingPolicy": { "Region": "us-west-1" } } }, // ... ] }
Failover Routing- route traffic if primary endpoint is unhealthy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
{ "Changes": [ { "Action": "UPSERT", "ResourceRecordSet": { "Name": "example.com", "Type": "A", "SetIdentifier": "Primary", "FailoverRoutingPolicy": { "FailoverBehavior": "PRIMARY" }, "TTL": 300, "ResourceRecords": [{ "Value": "34.229.79.211" }] } }, { "Action": "UPSERT", "ResourceRecordSet": { "Name": "example.com", "Type": "A", "SetIdentifier": "Secondary", "FailoverRoutingPolicy": { "FailoverBehavior": "SECONDARY" }, "TTL": 300, "ResourceRecords": [{ "Value": "34.229.79.111" }] } } ]}
Geolocation Routing- route traffic based on your users’ location
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
{ "Changes": [ { "Action": "UPSERT", "ResourceRecordSet": { "Name": "example.com", "Type": "A", "SetIdentifier": "US-East", "GeoLocationRoutingPolicy": { "CountryCode": "US" }, "TTL": 300, "ResourceRecords": [{ "Value": "34.229.79.211" }] } }, { "Action": "UPSERT", "ResourceRecordSet": { "Name": "example.com", "Type": "A", "SetIdentifier": "EU-West", "GeoLocationRoutingPolicy": { "CountryCode": "EU" }, "TTL": 300, "ResourceRecords": [{ "Value": "34.229.79.111" }] } } ]}
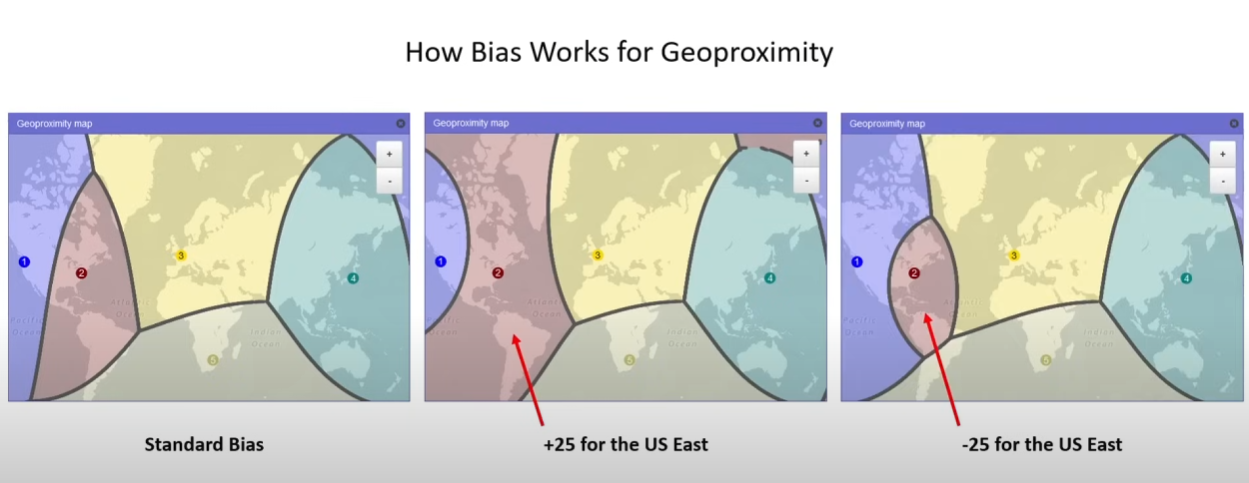
Geo-proximity Routing- route traffic based on the location of your resource and optionally shift traffic from resources in one location to resources in another
- must use
Traffic Flowto use this type of routing
Multi-value Answer Routing- responds to DNA queries with up to eight healthy records selected at random
- very similar to
Simplebut with added health check1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
{"Changes": [{ "Action": "UPSERT", "ResourceRecordSet": { "Name": "www.example.com", "Type": "A", "TTL": 60, "MultiValueAnswerRoutingPolicy": { "EvaluateTargetHealth": true }, "ResourceRecords": [ { "Value": "34.229.79.211"}, { "Value": "14.229.29.21"}, { "Value": "3.209.80.38"}, ] } }]}
Health Checks
- useful to check if something is healthy, if not route traffic elsewhere
- can create
CloudWatch Alarmof status unhealthy - checks health every 30s by default, but can be reduced to 10s
- up to 50 health checks within/linked same AWS account
- more expensive for non AWS endpoints
Resolver
- allows you to resolve DNS queries between your on-prem network and your VPC
- if you want your DNS server to work with your VPC, use this guy
DNSSEC
- Domain Name System Security Extensions
- suite of extension specifications by Internet Engineering Task Force (IETF) for securing data exchanged in the Domain Name System (DNS) in Internet Protocol (IP) networks -
DNSSEClets DNS resolvers validate that a DNS response came from Route53 and has not been tampered with - You need to create a
KSKsigning key and enable it - important to enable so people cannot impersonate your domain
- complex process
1
2
3
4
5
6
7
aws route53 create-key-signing-key \
--region <> \
--hosted-zone-id <> \
--key-management-service-arn <> \
--name <> \
--status ACTIVE \
--caller-reference <some_unique_string>
1
2
3
aws route53 enable-hosted-zone-dnssec \
--hosted-zone-id <> \
--region <>
Zonal Shift
- capacility in Route53 Application Recovery Controller (ARC)
- Shifts an LB resource away from am impaired AZ to healhy AZ with a single action
- only supported on ALB and NLB with cross-zone load balancing turned off
Profiles
- allows you to manage DNS-related Route53 configs across many VPCs and in different AWS accounts
- create profile; attach resources
Global Accelerator
- find the optimal path from the end user to your web-servers.
- deployed within
Edge Locations, so you send user traffic to an Edge Location instead of directly to your web app - 2 types:
Standard– automatically route to the nearest healthy endpointCustom Routing– route to specific EC2 instances
- listeners, Endpoints groups, endpoints …
CloudFront
- Content Delivery Network
CDNis a distributed network of servers that delivers web pages and content to users based on their geographical logcatio, the origin of the webpage, and content delivery server - CloudFront is a CDN that be used to deliver:
- Static/Dynamic Content
- Streaming Videos
- Web Sockets
- can be fronted with AWS WAF for OWASP TOP 10 protection
- can be used to stream videos On Demand using ISS Microsoft Smooth Streaming
- Core Components:
Lambda@Edge
- override the behavior of requests and responses
- supported languages: Python and Node.JS
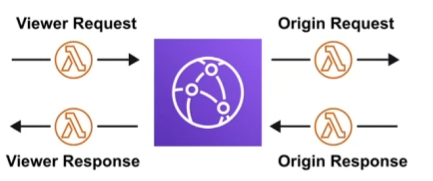
- deployed at
Regional Edge Caches - There are 4 functions for Lambda@Edge
Viewer request– When CloudFront receives a request from a viewer- use cases: redirect http(s), inspect cookies for user auth, modify headers
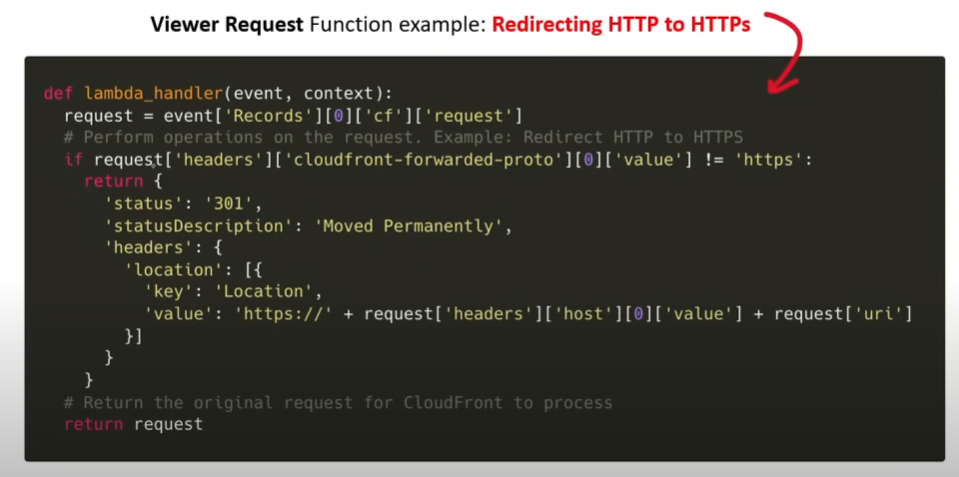
- use cases: redirect http(s), inspect cookies for user auth, modify headers
Origin Request– Before CloudFront forwards a request to the origin- use cases: rewrite URLs for SEO or routing, inject headers for origin auth, selective content serving based on user-agent
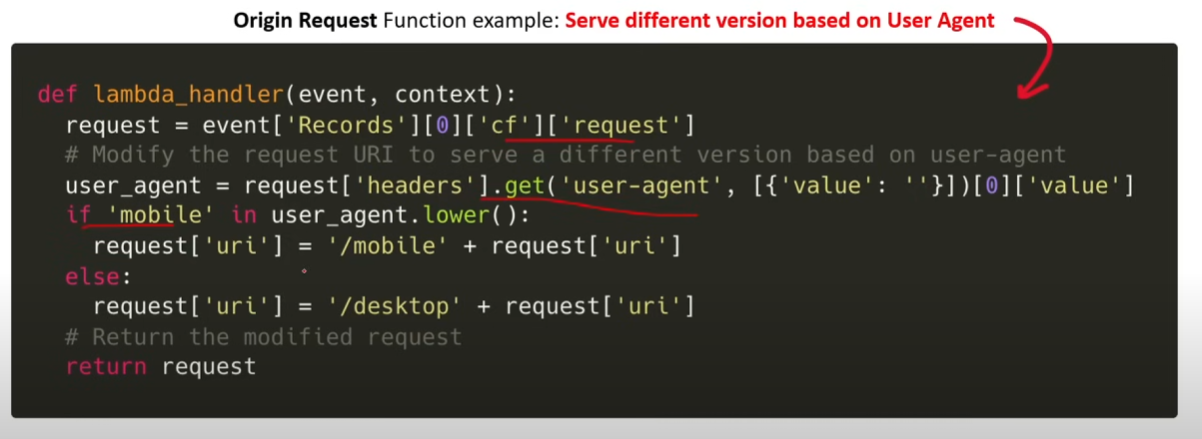
- use cases: rewrite URLs for SEO or routing, inject headers for origin auth, selective content serving based on user-agent
Origin Response– When CloudFront receives response from the origin- use cases: modify headers, update URLs in html for versioning, customize err responses from the origin
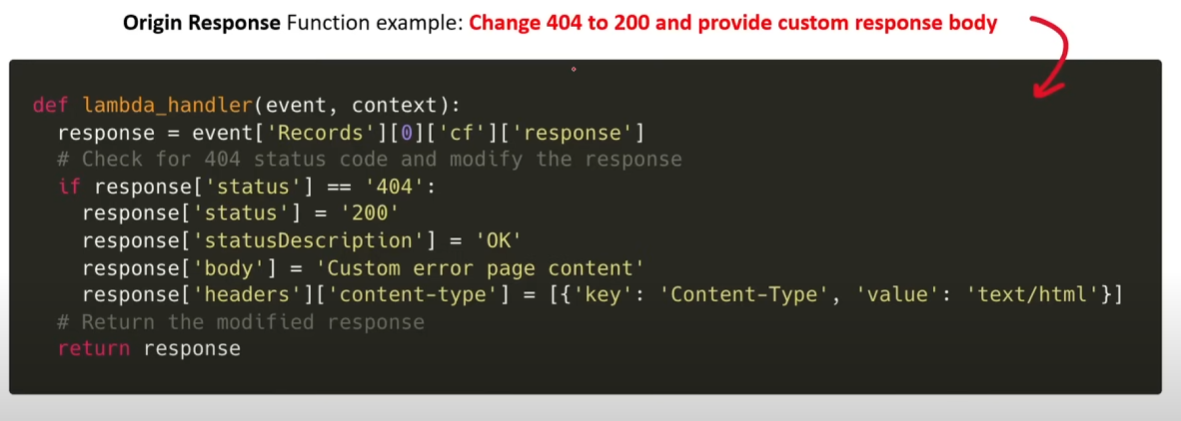
- use cases: modify headers, update URLs in html for versioning, customize err responses from the origin
Viewer Response– Before CloudFront returns the response to the viewer- use cases: add security headers (CSP, HSTS), set cookies for client-side tracking, customize err msgs

- use cases: add security headers (CSP, HSTS), set cookies for client-side tracking, customize err msgs
Functions
- lightweight edge functions for high-scale latency-sensitive CDN customizations
- cheaper, faster, but more limited than Lambda@Edge
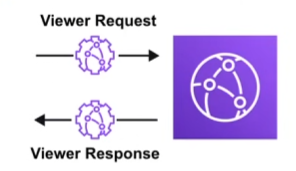
- There are 2 functions:
Viewer requestandViewer Response - supported languages: JavaScript (ECMAScript 5.12 compliant)
- deployed to edge locations
- use cases: cache key normalization, header manipulations, status code modifications, URL redirects, request authorization
Lambda@Edge vs Functions
- Lambda@Edge are more expensive; use Functions when you can
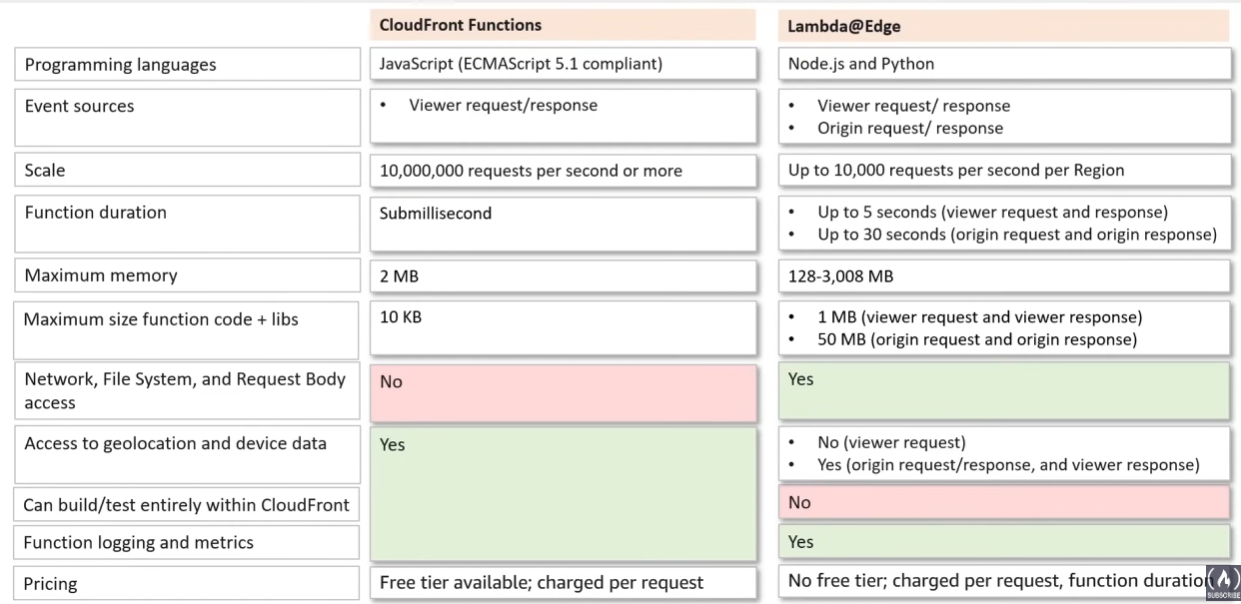
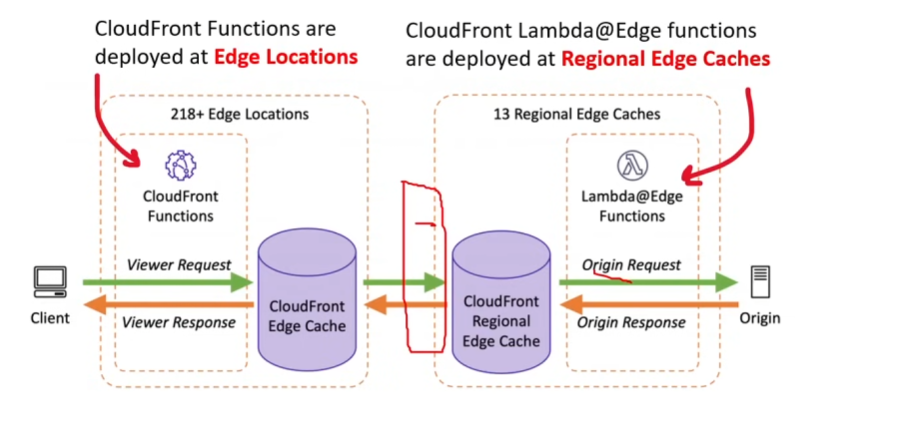
Origin
- the source where CloudFront will send requests
Domain Name– address to the originOrigin Path– the path at the specified addressS3OriginConfiorCustomOriginConfig
EBS
IOPSInput/Output Per Second. Speed at which non-contiguous reads and writes can be performed on a storage medium. High I/O = lots of small, fast, reads and writesThroughput(water) data transfer rate to and from the storage medium in megabyte per secondBandwidth(pipes) measurement of total possible speed of data movement along the network- Elastic Block Store is a highly available and durable solution for attaching persistent block storage volumes to an EC2 instance.
- automatically replicated within their AZs
- Types:
- general purpose SSD (
gp2) – usage w/o specific requirements - general purpose SSD (
gp3) – up to 20% lower cost per GB than gp2 - Provisioned IOPS SSD (
io1) – when you required really fast I/O - Provisioned IOPS SSD (
io2) – more durable than io1 (does not exist anymore; use io2 Block Express) io2 Block Express– higher throughput and IOPS and support larger storage capacity- Cold HDD (
sc1) – Lowest cost HDD volume for infrequently accessed workloads - Throughput Optimized HDD (
st1) – magnetic drive optimized for quick throughput - Magnetic (
standard) – previous generation HDD
- general purpose SSD (
Volume Type Usage
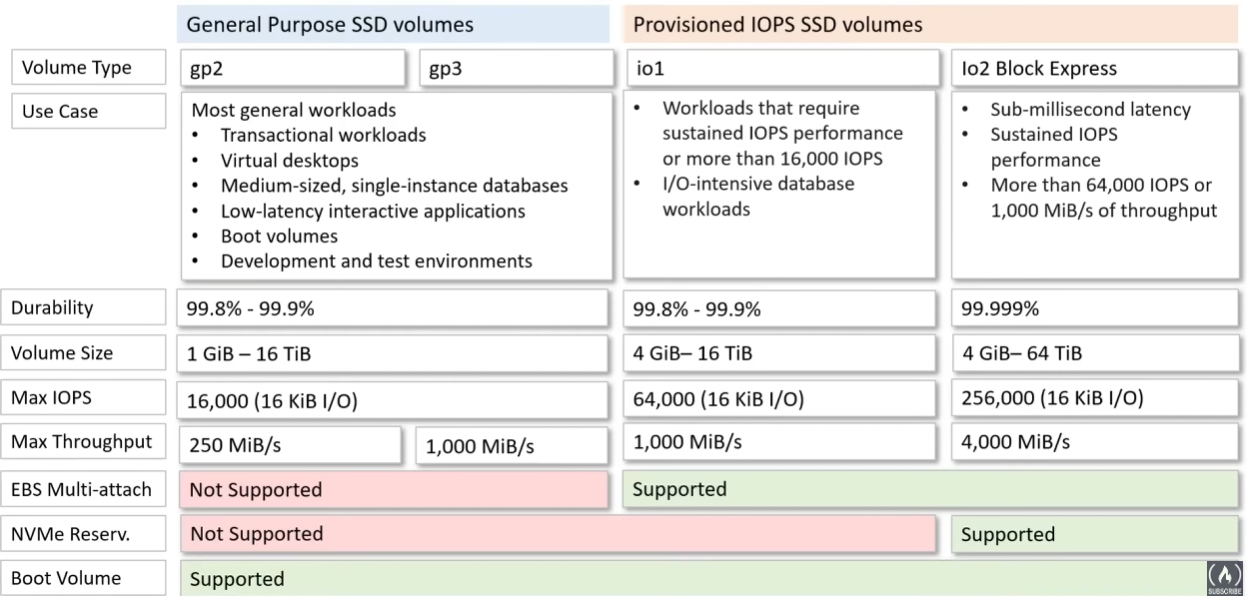

HDD

- magnetic storage that uses rotating platters
- very good at writing a continuous amount of data
- not great for writing many small writes or reads
RPM(revolutions per minute)5400 RPM Drives– Often used in laptops, external hard drives, and applications where lower power conspution and heat are priorities over performance7200 RPM Drives– std for desktops and high-performance external drives, offering a good balance of cost, performance, and power consumption10000 RPM Drive– enterprise environments or high-end workstations. less common due to rise of SSDs
RAID
- Redundant Array of Independent Disks
- data storage virtual technology for magnetic disks (not magnetic tape) to improve fault tolerance
- stores data across disks
- common types:
RAID 0(Striping)- No redundancy; data is split across disks for high performance
- Inc speed and capacity but offers no fault tolerance
- Min of 2 disks required
RAID 1(Mirroring)- Data is duplicated on two or more disks
- if one disk fails, data is accessible from another
- requires at least 2 disks
RAID 5(Striping w/ Parity)- combined striping and parity for both speed and data protection
- can withstand the failure of one drive w/o data loss
- requires at least 3 disks
RAID 6(Striping w/ Double Parity)- similar to RAID 5 but with double parity, allowing it to survive the failure of two disks
- requires at least 4 disks
RAID 10(1+0)- A combination of RAID 1 and RAID 0, offering redundancy and incread performance
- min of 4 disks required
SSD
- solid state drive

- uses integrated circuit (IC) assemblies as memory to store data typically using flash memory
- resistant to phyiscual shock, run silently, and have quicker access time and lower latency
- Types:
SATA– widely used, good performance but slower than NVMe due to SATA interface
NVMe– use the PCIe interface for higher performance. ideal for intensive tasksM.2– compact, sutiable for laptops. Can use SATA or NVMe interfaces
U.2– similar to M.2 NVMe but designed for 2.5-inch drive bays. mainly used in enterprise
Portable– external drives for easy portabilityPCIe– add-on cards that provide high performance for older systems, fitting in PCIe slots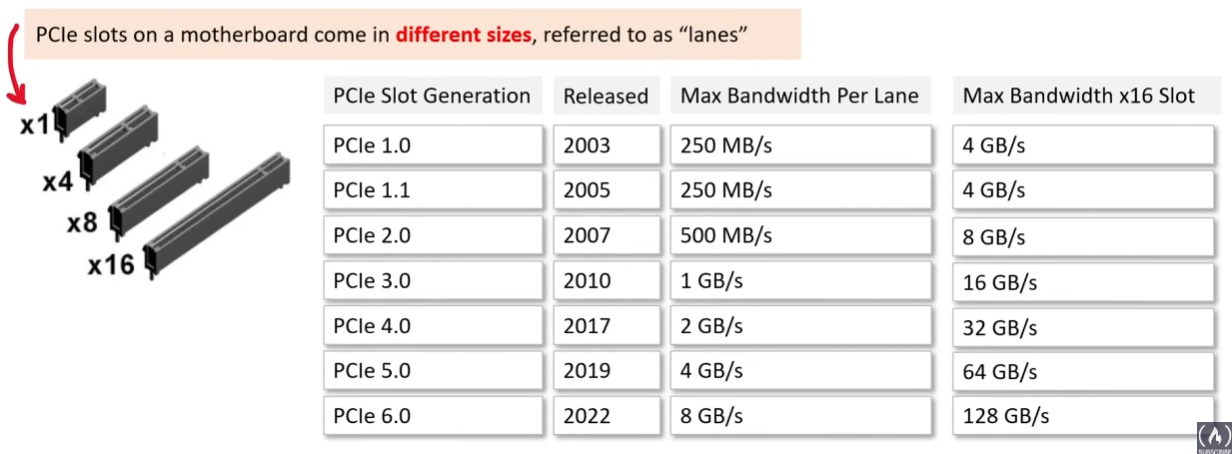
Magnetic Tape
- cheap and can be used to store enormous data and can last for 30 years at least

EFS
- Elastic File System
- File storage service for EC2 instances
- grows up to petabytes and shrinks automatically
- multiple EC2 instances on the same VPC can mount to a single EFS volume (volume in the same VPC)
- EC2 instances install
NSFv4.1 protocolclient and can then mount - EFS creates multiple mount targets in all your VPC subnets
- you can mount to lambdas and fargate as well
EFS Client
amazon-efs-utilsopen-source collection of EFS tools- https://github.com/aws/efs-utils
- enables ability to use CloudWatch to monitor an EFS mount status
- install prior to mounting
sudo yum install -y amazon-efs-utils- come with
mount helperwhich has a lot of features that ease the mounting process mount helperconfigs located at/etc/fstab
FSx
- allows you to deploy scale feature-rich high-performance file systems in the cloud.
- supports a variety of file system protocols:
NetApp ONTAP– enterprise storage platform known for handling petabytes of dataOpenZFS– open-source storage platform originally developed by Sun MicrosystemsWindows File Server (WFS)– supports native window features for Windows developersLustre– open-source file system for parallel computing

File Cache
- High speed cache for datasets stored anywhere, accelerate cloud bursting workloads

Backup
- centrally manage backups across AWS services
- S3, VMWares, Dynamo, EFS/EBS/EC2, SGW, RDS, Neptune, DocumentDB… etc
- set up a
Backup Plan– defines the backup schedule, window, and lifecycle - stuff is stored in a
Backup Vault– where backups are stored- allows for WORM to set a retention period
- std vault (default) – backups are always initially stored here
- air-gapped vault – can be moved to a logically air-gapped vault for additional security
- you can backup resources to other Regions or Accounts
- backups are incremental, so you only store the difference instead of the full backups to save costs
- can use KMS for encryption
- backups are immutable to avoid them being tampered with
AWS Backup Audit Manageris built-in reporting and auditing for AWS backups
Snow Family
- storage and compute devices used to physically move data in or out the cloud when moving data over the internet or private connection is too slow, diffiuclt or costly.

Snowcone
- portable, rugged, and secure device for edge computing and data transfer
- can send data to AWS in 2 way:
- physically shipping the device back to AWS
- use
AWS DataSyncwhich runs on the device’s compute
- small, light to carry
- can run edge computing workloads on its EC2 instances
- light workload (25% CPU) run for up to ~6 hours
- offer an interface with
Network File System (NFS)support for windows, Linux, and macOS - use the Wi-Fi interface to gather sensor data (NA only)
- multiple layers of encryption
- can collect IoT data using
AWS IoT Greengrass - does not come with cables (check AWS)
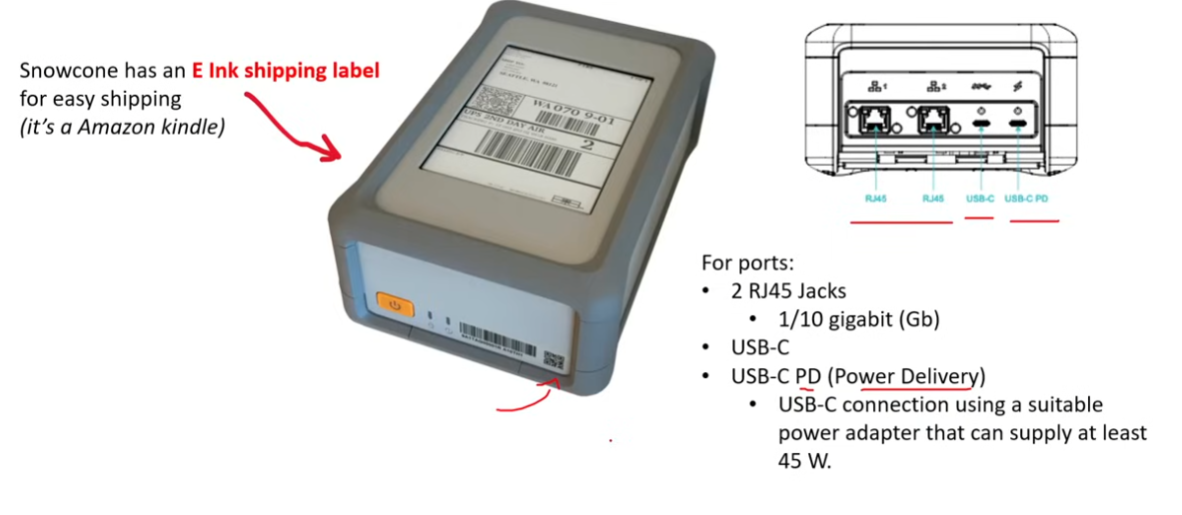
Snowball Edge
- similar to snowcone but with more local processing and edge computing workloads and device configs
- LCD display
- can be used in a cluster of 3 to 16 nodes
- supports data transfer protocols:
NSFv3v4andv4.1orS3over HTTP(S) - 5 device configuration options:
- Storage optimized (for data transfer) – 100 TB (80 usable)
- storage optimized 210 TB – 210 TB usable
- storage optimized w/ EC2 compatible compute – 80 TB usable, 40 vCPUs, and 80 GB of mem
- compute optimized – up to 104 vCPUs, 416 GB mem, 28 dedicated NVMe SSD
- compute optimized with GPU – addition of GPUs
Snowmobile
- 45 ft long ruggedized shipping container, pulled by a semi-trailer truck.
- 100PB per
- 24/7 surveillance, GPS tracking, alarm monitoring, (optional) security vehicle escort

Tansfer Family
- offer fully manager support for transfer of files over
SFTP,AS2,FTPS, andFTPdirectly into and out ofS3orEFS FTP– File Tansfer Protocol: early network protocol without encryption (port 20 for control commands and port 21 for data transfer)SFTP– Secure version of above… uses SSH to provide secure connection for transferring files (port 22)FTPS– FTP Secure or FTP-SSL: extends FTP with support for SSL/TLS encryption (port 990)AS2– Applicability Statement 2: enables secure and reliable messaging over HTTP/S often used for Electronic Data Interchange (EDI) transactions. used in e-commerce and retail that require proff of compliant data transfers (port 443).
MFTW
- Managed File Transfer Workflows
- fully managed serverless file transfer workflow service to set up, run, automate and monitor processing of files uploaded using AWS Transfer Family
- allows you to copy, decrypt, tag, delete, and create custom file-processing steps (pass to lambda)
Migration Hub
- single place to discover existing servers, plan migrations and track status
- us-east-1

DataSync
- works with following protocols: NFS, SMB, HDFS, and object storage
- works w/ AWS services: S3, EFS, FSx for WFS, Lustre, OpenZFS, NetApp ONTAP
- works w/ other cloud providers: GCP, Azure blob, Wasabi, Alibaba, Cloudflare, Digital Ocean…
DMS
- data migration service
- quickly and securely migrate your on-prem database to AWS
AWS Schema Conversion

- Migration Methods:
- Homogeneous data migration – using native database tools (e.g. pg_dump, pg_restore)
- Instance replication – provision an instance with chose instance type
- serverless replication –
- pay as you go w/ some limitations.
- must use VPC endpoints
- limited selection of sources and targets
- does not support views w/ selection and transformation rules
TablePlusapp for db connections (handy)
Schema Conversion Tool
- SCT
- stand-alone desktop app to convert your db schema to another db engine
- can be installed on linux (fedora and ubuntu), wondows, but NOT mac
Auto Scaling
- Auto Scaling Group (ASG)
- service that can discover scaling resources within your AWS account, and quickly add scaling plans
- can be used for: EC2/ECS, Aurora, DynamoDB, Spot Fleet
Amplify
- an opionionated framework and fully-managed infra to allow developers to focus on building web and mobile apps
- Includes:
- Amplify CLI – unified toochain to create, integrate, and managhe the AWS cloud services
- Amplify SDK – connects AWS services to your client-side code
- Amplify UI – collection of accessible, themeable, performant React components directly connect to cloud
- Amplify Hosting – static website hosting platform (they hide the cloudfront and s3 bucket from you so not worth it + it has extra cost)
- Amplify Studio – visual dev env for building fullstack web and mobile apps Integrates with: Cognito, AP gateway, AppSync, S3, DynamoDB, AWS lambda supported frameworks: React, JS, Flutter, Swift, Android, React native, Angualar, Next.JS, Vue
- This service has never lived up to delivering on Developer Experience (DX)
AppFlow
- managed integration service for data transfer between data sources
- easily exchange data w/ over 80+ cloud services by specifying a source and a destination
S3 =Flow=> Google Sheets - Flow triggers:
- Run on demand
- Run on event
- Run on schedule Features:
- create fataflows between apps
- aggregate data from multiple sources
- data can be encrypted at rest and transit
- use partition and aggregation settings to optimize query performance
- develop custom connectors via SDKs
- create
private flowvia AWS PrivateLink - can catalog data transferred to S3 via
AWS Glue Data Catalog

AppSync
- fully managed GraphQL service
- supports custom domains and has a query editor in the UI
resolversattach to specific fields within your types in your schema- API types:
- GraphQL
- Merged (collection of Graph API)
- Data sources:
- Dynamo
- OpenSearch
- Lambda
- HTTP endpoint
- Eventbridge
- RDS (http endpoint)
- caching options:
- none
- full
- per-resolver
- Auth:
- API key
- AWS IAM
- Cognito user pool
- resolver runtimes:
- APPSYNC_JS – JS
- VTL – Velocity Template Language
GraphQL
- open-source agnostic query adapter that allows you to query data from many diff data sources
- used to build APIs where clients will send a query for nest data
- mitigates the issue of versioned or rapidly changing APIs compared to REST API because you can request the data you want
- GraphQL schemas are written in the GraphQL SDL (Schema Definition Language) composed of:
- Types – represent objects and their fields
- Fields – name, age, whatever
- Queries – defines the shape of data you want back from client
- Mutations – Creation, update, delete
- Subscriptions – supports live update from server to client
Batch
plans, schedules, and executes your batch computing workloads across the full range of AWS compute services
Jobs– names unit of work, e.g. shell script, docker imageJob definitions– defines how to run the job, e.g. compute & memoryJob Queues– a collection of jobs that determines job priorityJob Scheduler– evaluates when/where/how to run jobs that are submitted to a job queue (FIFO by default)- can run jobs on: EKS, Fargate, EC2
- Other concepts: Array jobs, multi-node parallel jobs, GPU jobs, job dependencies
- not a super useful or easy to use service
OpenSearch
- full-text search service that makes it easy to deploy, operate, and scale OpenSearch
- OpenSearch is an open-source fork of open-source Elasticsearch 7.10.2 and Kibana 7.10.2
- it is a search and analytics engine
- 2 engines: OpenSearch and ElasticSearch
- Elasticsearch is a search engine based on the Lucene lib
ELKstack: Elasticsearch, Logstash, and KibanaElasticsearch– full-text search and analytic engineLogstash– data processing pipelineKibana– viz layer for stored data
DeviceFarm
- app testing service to test your app in diff env
- you can test native iOS (.ipa) or Android (.apk) or Mobile Web-Apps
- you can use built-in tests Fuzz which will randomly test actions
- videos/screenshots will be capture of runs
- you can choose multiple devices (you can remotely connecting to real physical phones)
- you can test using Appium suite (Java Junit, Test NG, Python, Node.js, Ruby)
QLDB
Quantum Ledger Database is a fully managed ledger database that provides transparent, immutable, and cryptographically variable transaction logs.
Features:
- Immutable Logs
- cryptographic verification – sha256
- fully managed
- serverless
- sql-like queries
- central governance
- high throughput and scalability
- AWS integration
- ACID Transactions – Atomic, Consistent, Isolated, and durable transactions
- Journal Storage
Elastic Transcoder
Fully-managed video-transcoding service that converts videos from one format to another for Video On Demand (VoD) or streaming video
- very expensive. better off with EC2 running
ffmpegwithS3orEBSfor storage. - does not support CFN, only SDK and CLI
- legacy but easy to use.
AWS Elemental MediaConverttook over but is more complicated.
Elemental MediaConvert
Fully-managed video-transcoding service that converts videos from one format to another for Video On Demand (VoD) or streaming video + applying lots of additional processing options

SNS
- highly available, durable, secure, fully managed
pub/submsging service. - std msg size = 256KB, but you can do up to 2GB using
amazon-sns-python-extended-client-libor similar libs 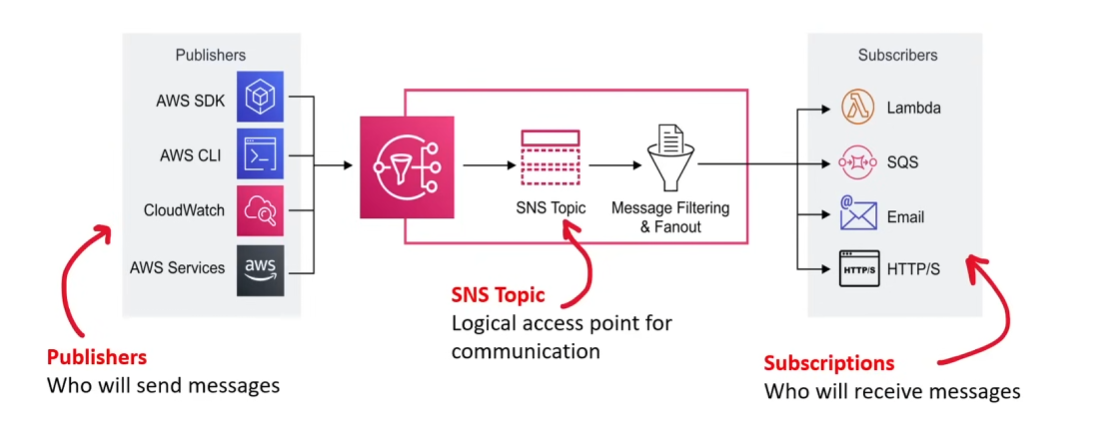



Pub/Sub
- Publish-subscribe pattern commonly implemnented in msging systems.
publisherdoes not send to receivers- instead, send their msg to an
event bus event buscategorizes the msgs into groupssubscriberssubscribe to these groupspublishersdo not know who their subs are- subs do not pull for msgs; msgs are automatically and immediately pushed to subs
Filter Policy
- allows you to filter a subset of msgs
- Filter Policy scope:
MessageAttributesorMessageBody - Filtering Options:
- And logic
- Or logic/operator
- key matching
- numeric value exact/anything-but/range matching
- string value exact/anything-but matching
- string matching using prefix/suffix matching
- string value equals-ignore case
- string value IP address matching
Message Data Protection
- safeguards the data published to your SNS topics
- it can audit, mask, redact or block sensitive data
- scans for (via data identifiers):
- Personally Identifiable Information (PII)
- Protected Health Information (PHI)
- data identifiers:
- name
- address
- credit card
- custom created
- supported actions:
- audit – audit up to 99% of data published
- de-identify – redact
- deny – block data from being sent\
- only supported for STANDARD SNS Topics
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
{
"Name": "policyname",
"desc": "",
"version": "",
"Statement": [
{
"dataDirection": "Inbound",
"Principal": [
"arn:aws:iam::<>:user/Exampleuser"
],
"Dataidentifier": [
"arn:aws:dataprotection::aws:data-identifier/CreditCardNumber"
],
"operation": {
"Deidentify" : {
"MaskConfig": {
"MaskWithCharacter": "#"
}
}
}
}
]
}
Raw Message Delivery
- avoid having Amazon Data Firehose, SQS, and HTTP/S endpoints process the JSON formatting of msgs
- Firehose and SQS – metadata is stripped from the published msgs and the msg is sent as is.
- HTTP/S – header
x-amz-sns-rawdeliverywith its value set to true, indicating the msg should not be formatted
1
2
3
4
aws sns set-subscription-attributes \
--subscription-arn <> \
--attribute-name RawMessageDelivery \
--attribute-value true
Delivery Policy

- HTTP/S are custom configured
1
2
3
4
aws sns set-subscription-attributes \
--subscription-arn <> \
--attribute-name DeliveryPolicy \
--attribute-value file://<>.json
backoffFunctioncan also bearithmeticorgeometricorlinear
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"healthyRetryPolicy" : {
"minDelayTarget": 1,
"maxDelayTarget" 60,
"numRetries": 50,
"numNoDelayRetries": 3,
"numMinDelayRetries": 2,
"numMaxDelayRetries" 35,
"backoffFunction": "exponential"
},
"throttlePolicy" : {
"maxReceivesPerSecond": 10
}
"requestPolicy" : {
"headerContentType": "application/json"
}
}
Dead Letter Queue
- failed msg attempts to an SQS queue
- std SNS –> std SQS
- FIFO SNS –> FIFO SQS